//循环插入每个节点 for (Object o : a) { @SuppressWarnings("unchecked") E e = (E) o;//向下转型 Node<E> newNode = new Node<>(pred, e, null);//生成一个新节点 //前驱为空,表示在第一个位置插入 if (pred == null) first = newNode; //否则在index前面插入新节点 else pred.next = newNode; pred = newNode; } { //后继为空 if (succ == null) last = pred;//在末尾插入 } else { //否则链接最后的节点 pred.next = succ; succ.prev = pred; }
//集合转数组 public Object[] toArray() { Object[] result = new Object[size]; int i = 0; for (Node<E> x = first; x != null; x = x.next) result[i++] = x.item; return result; }
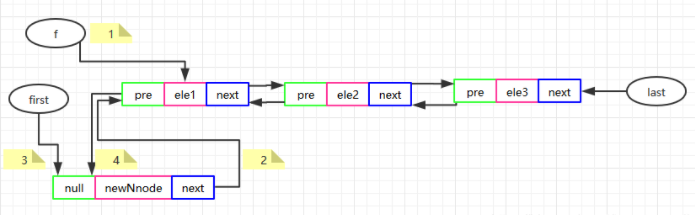
//在头部插入一个新节点 privatevoidlinkFirst(E e){ //因为需要把插入的该元素设置为头节点,所以需要新建一个变量把原来的头节点存储起来。 final Node<E> f = first; //然后新建一个节点,保存插入节点的值e,由于插入的节点为头结点,因此前驱为null,而后继则为原来的头结点 final Node<E> newNode = new Node<>(null, e, f); //将头结点引用指向新节点 first = newNode; //如果原来的头结点为空,则说明没有头结点,头尾节点均为null if (f == null) //将新节点置为尾结点 last = newNode; else //否则原来的头结点的前引用指向新节点 f.prev = newNode; //size和modCount自增 size++; modCount++0; }
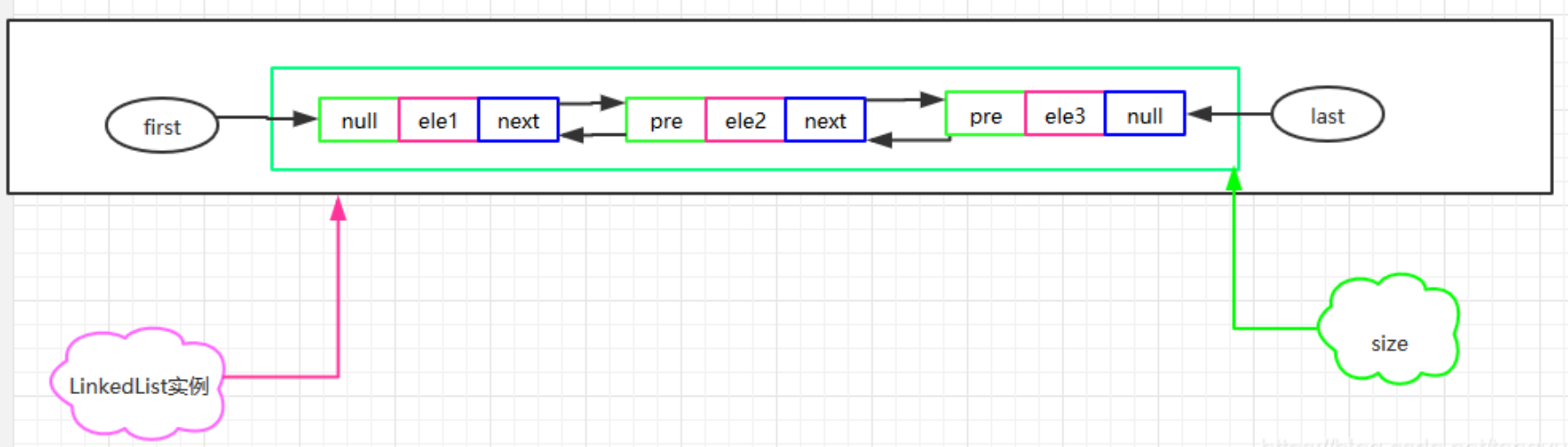
图解如下:
linkLast(E e)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
//在尾部插入一个新节点 voidlinkLast(E e){ //因为需要把插入的该元素设置为尾节点,所以需要新建一个变量把原来的尾节点存储起来。 final Node<E> l = last; //然后新建一个节点,保存插入节点的值e,由于插入的节点为尾结点,因此前驱为l,而后继则为null final Node<E> newNode = new Node<>(l, e, null); //last引用指向新节点 last = newNode; //如果原来的尾结点为空,则说明没有尾结点,则尾结点为新节点 if (l == null) first = newNode; else //否则原来尾结点的后引用指向新的尾结点 l.next = newNode; size++; modCount++; }
过程与头部插入节点类似。
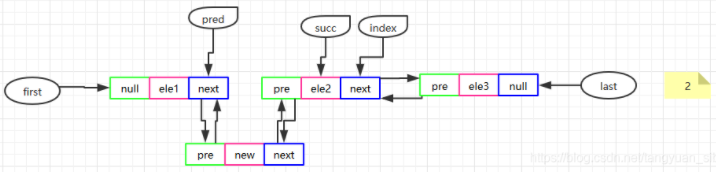
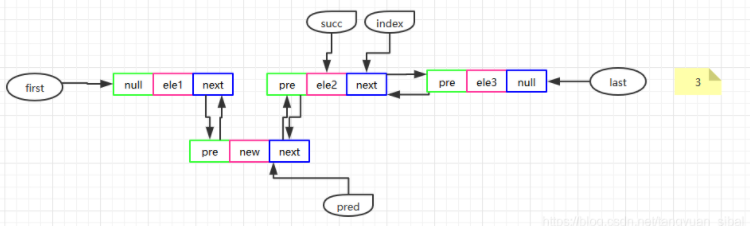
linkBefore(E e, Node succ)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
//在某个节点之前插入一个新节点 voidlinkBefore(E e, Node<E> succ){ // assert succ != null; //找到该节点的前一个节点,因为要在succ前面插入一个节点 final Node<E> pred = succ.prev;// //新节点的前一个节点就是原来succ的前一个节点(pred),后一个节点当然就是succ final Node<E> newNode = new Node<>(pred, e, succ); succ.prev = newNode; //如果pred为空,说明要插入的节点位置为第一个节点 if (pred == null) first = newNode; else //否则pred的下一个节点就是新节点 pred.next = newNode; size++; modCount++;
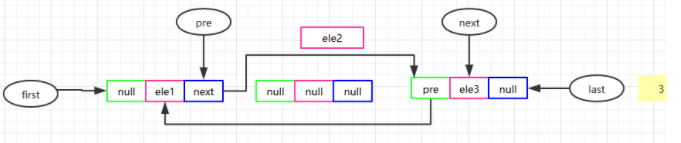
//删除LinkedList中第一个节点(该节点不为空,并且返回删除的节点的值) private E unlinkFirst(Node<E> f){ // assert f == first && f != null; // //(因为我们需要设置f节点的下一个节点为头结点,而且需要把f节点的值设置为空) // //接着判断一个它的下一个节点是否为空,如果为空的话,则需要把last设置为空。否则 //的话,需要把next的prev设置为空,因为next现在指代头节点。 //定义一个变量element指向待删除节点的值, final E element = f.item; //接着定义一个变量next指向待删除节点的下一个节点。 final Node<E> next = f.next; //接着把f的值和它的next设置为空,把它的下一个节点设置为头节点。 f.item = null; f.next = null; // help GC 解开与下一个元素的连接,方便GC回收 first = next; //如果待删除节点的下一个节点为空,说明LinkedList中就一个元素 if (next == null) //则需要把last设置为空。 last = null; else //断开后一个节点与待删除节点的连接 next.prev = null; size--; modCount++; return element; }
unlinkLast(Node l)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
//删除LinkedList的最后一个节点。(该节点不为空,并且返回删除节点对应的值) //思路和unlinkFirst()方法差不多。 private E unlinkLast(Node<E> l){ // assert l == last && l != null; final E element = l.item; final Node<E> prev = l.prev; l.item = null; l.prev = null; // help GC last = prev; if (prev == null) first = null; else prev.next = null; size--; modCount++; return element; }
//计算指定索引上的节点(返回Node) Node<E> node(int index){ // assert isElementIndex(index); //比较index更靠近链表(LinkedList)的头节点还是尾节点。然后进行遍历,获取相应的节点。 if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } }
removeFirst()
1 2 3 4 5 6 7 8 9
//提供给用户使用的删除头结点,并返回删除的值。 //直接调用了上面的工具方法unlinkFirst(Node f) public E removeFirst(){ final Node<E> f = first; if (f == null) thrownew NoSuchElementException(); return unlinkFirst(f); }
removeLast()
1 2 3 4 5 6 7 8 9
//删除链表中的最后一个节点,并返回被删除节点的值。 //和上面一样调用了unlinkLast(Node last)方法。 public E removeLast(){ final Node<E> l = last; if (l == null) thrownew NoSuchElementException(); return unlinkLast(l); }
//判断LinkedList是否包含某一个元素,底层通过调用indexof()。 //该方法主要用于计算元素在LinkedList中的位置。 //思路:先依据obejct是否为空,分为两种情况,然后通过在每种情况下,从头节点开始遍历LinkedList,判断是否有与object相等的元素,如果有,则返回对应的位置index,如果找不到,则返回-1。 publicbooleancontains(Object o){ return indexOf(o) != -1; } publicintindexOf(Object o){ int index = 0; if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) return index; index++; } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) return index; index++; } } return -1; }
//从LinkedList中删除指定元素。(且只删除第一次出现的指定的元素,如果指定的元素在集合中不存在,则返回false,否则返回true) //该方法也是通过object是否为空分为两种情况去,之后与LinkedList中的每一个元素比较,如果找到了,就删掉,返回true即可。如果找不到,则返回false。 publicbooleanremove(Object o){ if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) { unlink(x); returntrue; } } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) { unlink(x); returntrue; } } } returnfalse; }
clear()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
//清空LinkedList中的所有元素 //该方法也简单,直接遍历整个LinkedList,然后把每个节点都置空,最后要把头节点和尾节点设置为空,size也设置为空,但是modCount仍然自增 publicvoidclear(){ // Clearing all of the links between nodes is "unnecessary", but: // - helps a generational GC if the discarded nodes inhabit // more than one generation // - is sure to free memory even if there is a reachable Iterator for (Node<E> x = first; x != null; ) { Node<E> next = x.next; x.item = null; x.next = null; x.prev = null; x = next; } first = last = null; size = 0; modCount++; }
get(int index)
1 2 3 4 5 6 7
//获取对应index的节点的值。 //通过node()方法返回其值。(node()方法依据索引的值返回其对应的节点。) public E get(int index){ checkElementIndex(index); return node(index).item; }
set(int index, E element)
1 2 3 4 5 6 7 8 9 10
//设置对应index的节点的值。 //首先检查一下索引是否合法,然后通过node()方法求出旧值,然后设置新值。最后把旧值返回回去。 public E set(int index, E element){ checkElementIndex(index); Node<E> x = node(index); E oldVal = x.item; x.item = element; return oldVal; }
add(int index, E element)
1 2 3 4 5 6 7 8 9 10 11
//在指定的位置上添加新的元素。 //在方法中先判断新添加的元素是否是位于LinkedList的最后,然后则直接调用linkLast()方法添加即可。否则的话,调用linkBefore()添加即可。 publicvoidadd(int index, E element){ checkPositionIndex(index);
if (index == size) linkLast(element); else linkBefore(element, node(index)); }
remove(int index)
1 2 3 4 5 6
//移除指定位置上的元素 public E remove(int index){ checkElementIndex(index); return unlink(node(index)); }
isPositionIndex(int index)
1 2 3 4 5
//判断新添加元素的时候,传进来的index是否合法,而且新添加的元素可能在LinkedList最后一个元素的后面,所以这里允许index<=size。 privatebooleanisPositionIndex(int index){ return index >= 0 && index <= size; }
checkElementIndex(int index)
1 2 3 4 5 6
//判断参数index是否是元素的索引(如果不是则抛出异常) privatevoidcheckElementIndex(int index){ if (!isElementIndex(index)) thrownew IndexOutOfBoundsException(outOfBoundsMsg(index)); }
checkPositionIndex(int index)
1 2 3 4 5 6
//判断新添加元素的时候,传进来的index是否合法,(调用的是isPositionIndex(index)方法)而且新添加的元素可能在LinkedList最后一个元素的后面,所以这里允许index<=size。如果不合法,则抛出异常。 privatevoidcheckPositionIndex(int index){ if (!isPositionIndex(index)) thrownew IndexOutOfBoundsException(outOfBoundsMsg(index)); }
lastIndexOf(Object o)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
//在LinkedList中查找object在LinkedList中的位置。(从后向前遍历,只返回第一出线的元素的索引,如果没找到,则返回-1) publicintlastIndexOf(Object o){ int index = size; if (o == null) { for (Node<E> x = last; x != null; x = x.prev) { index--; if (x.item == null) return index; } } else { for (Node<E> x = last; x != null; x = x.prev) { index--; if (o.equals(x.item)) return index; } } return -1; }




 微信
微信 支付宝
支付宝