MyCat-高可用集群搭建、架构剖析
MyCat高可用集群搭建
集群架构
MyCat实现读写分离架构
在之前的笔记中, 已经讲解过了通过MyCat来实现MySQL的读写分离,从而完成MySQL集群的负载均衡, 如下面的结构图:
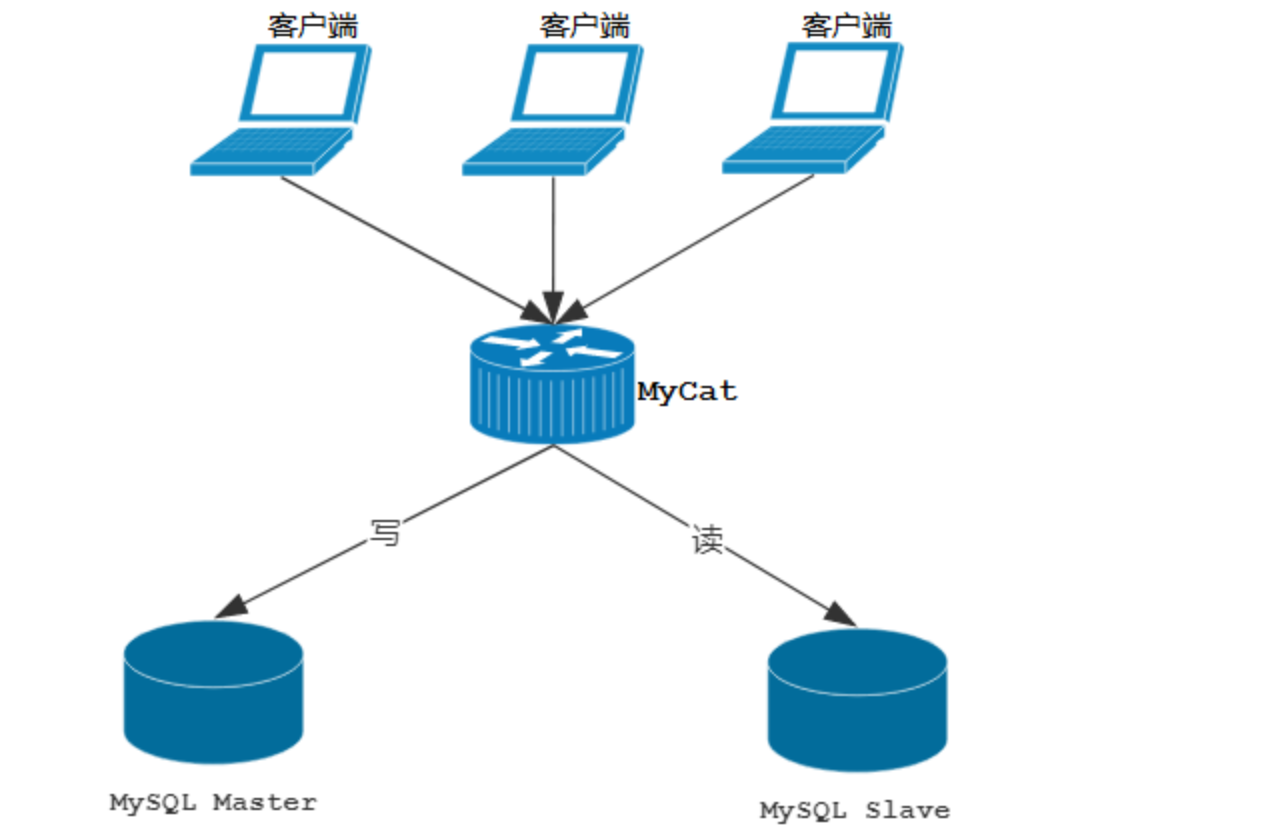
但是以上架构存在问题 ,由于MyCat中间件是单节点的服务,前端客户端所有的压力过来都直接请求这一台MyCat,存在单点故障。所以这个时候, 我们就需要考虑MyCat的集群 。
MyCat集群架构
通过MyCat来实现后端MySQL的负载均衡 ,通过HAProxy再实现MyCat集群的负载均衡:
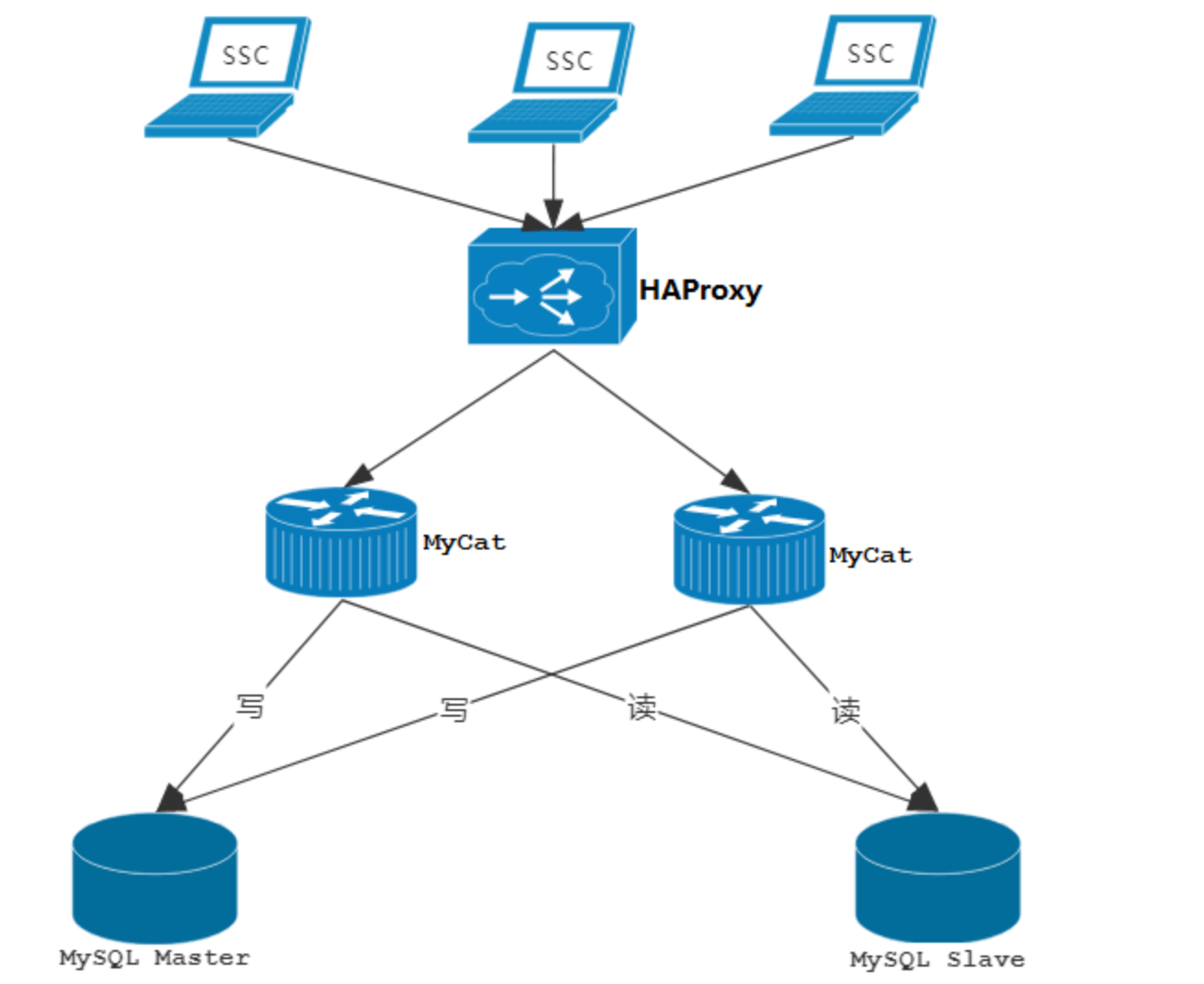
HAProxy 负责将请求分发到 MyCat 上,起到负载均衡的作用,同时 HAProxy 也能检测到 MyCat 是否存活,HAProxy 只会将请求转发到存活的 MyCat 上。如果一台 MyCat 服务器宕机,HAPorxy 转发请求时不会转发到宕机的 MyCat 上,所以 MyCat 依然可用。
HAProxy介绍:
HAProxy 是一个开源的、高性能的基于TCP(第四层)和HTTP(第七层)应用的负载均衡软件。 使用HAProxy可以快速、可靠地实现基于TCP与HTTP应用的负载均衡解决方案。
具有以下优点:
可靠性和稳定性好, 可以与硬件级的F5负载均衡服务器媲美 ;
处理能力强, 最高可以通过维护4w-5w个并发连接, 单位时间处理的最大请求数达到2w个 ;
支持多种负载均衡算法 ;
有功能强大的监控界面, 通过此页面可以实时了解系统的运行情况 ;
但是,上述的架构也是存在问题的, 因为所有的客户端请求都是先到达HAProxy,由HAProxy再将请求再向下分发,如果HAProxy宕机的话,就会造成整个MyCat集群不能正常运行,依然存在单点故障。
MyCat的高可用集群
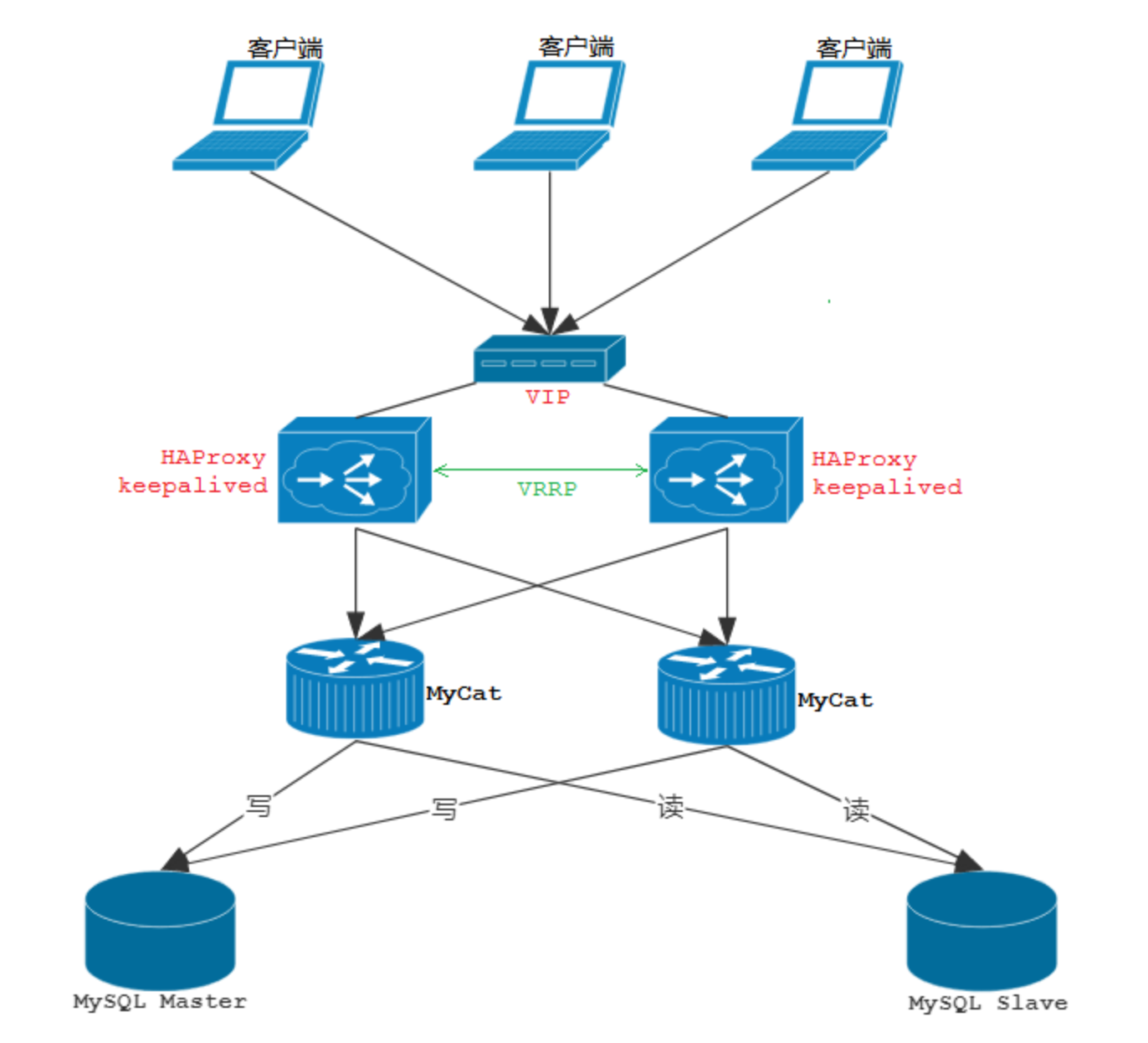
图解说明:
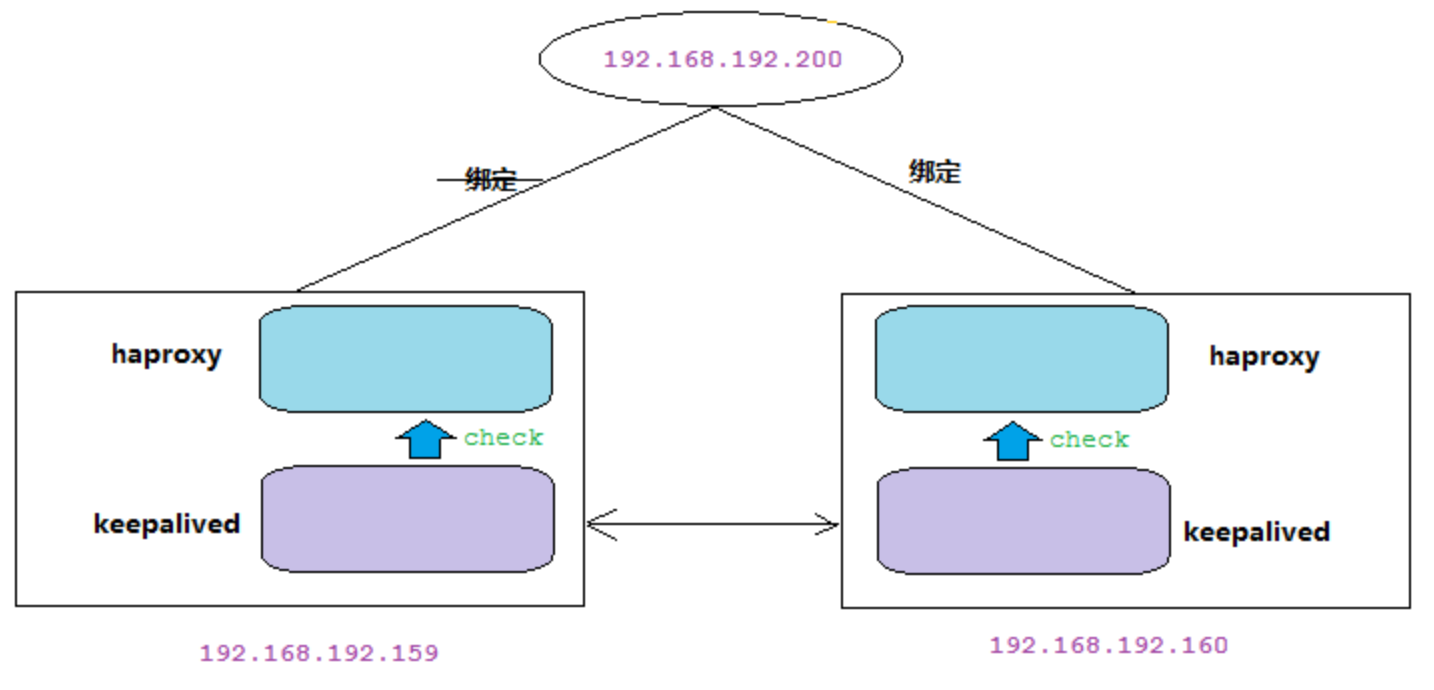
HAProxy 实现了 MyCat 多节点的集群高可用和负载均衡,而 HAProxy 自身的高可用则可以通过Keepalived 来实现。因此,HAProxy 主机上要同时安装 HAProxy 和 Keepalived,Keepalived 负责为该服务器抢占 vip(虚拟 ip),抢占到 vip 后,对该主机的访问可以通过原来的 ip访问,也可以直接通过 vip访问。
Keepalived 抢占 vip 有优先级,由keepalived.conf 配置中的 priority 属性决定。但是一般哪台主机上的Keepalived服务先启动就会抢占到vip,即使是slave,只要先启动也能抢到(要注意避免Keepalived的资源抢占问题)。
HAProxy 负责将 vip 上的请求分发到 MyCat 集群节点上,起到负载均衡的作用。同时 HAProxy 也能检测到 MyCat 是否存活,HAProxy 只会将请求转发到存活的 MyCat 上。
如果 Keepalived+HAProxy 高可用集群中的一台服务器宕机,集群中另外一台服务器上的 Keepalived会立刻抢占 vip 并接管服务,此时抢占了 vip 的 HAProxy 节点可以继续提供服务。
如果一台 MyCat 服务器宕机,HAPorxy 转发请求时不会转发到宕机的 MyCat 上,所以 MyCat 依然可用。
综上:MyCat 的高可用及负载均衡由 HAProxy 来实现,而 HAProxy 的高可用,由 Keepalived 来实现。
keepalived介绍:
- Keepalived是一种基于VRRP协议来实现的高可用方案,可以利用其来避免单点故障。 通常有两台甚至多台服务器运行Keepalived,一台为主服务器(Master), 其他为备份服务器, 但是对外表现为一个虚拟IP(VIP), 主服务器会发送特定的消息给备份服务器, 当备份服务器接收不到这个消息时, 即认为主服务器宕机 , 备份服务器就会接管虚拟IP, 继续提供服务, 从而保证了整个集群的高可用。
- VRRP(虚拟路由冗余协议-Virtual Router Redundancy Protocol)协议是用于实现路由器冗余的协议,VRRP 协议将两台或多台路由器设备虚拟成一个设备,对外提供虚拟路由器 IP(一个或多个),而在路由器组内部,如果实际拥有这个对外 IP 的路由器如果工作正常的话就是 MASTER,或者是通过算法选举产生。MASTER 实现针对虚拟路由器 IP 的各种网络功能,如 ARP 请求,ICMP,以及数据的转发等;其他设备不拥有该虚拟 IP,状态是 BACKUP,除了接收 MASTER 的VRRP 状态通告信息外,不执行对外的网络功能。当主机失效时,BACKUP 将接管原先 MASTER 的网络功能。
- VRRP 协议使用多播数据来传输 VRRP 数据,VRRP 数据使用特殊的虚拟源 MAC 地址发送数据而不是自身网卡的 MAC 地址,VRRP 运行时只有 MASTER 路由器定时发送 VRRP 通告信息,表示 MASTER 工作正常以及虚拟路由器 IP(组),BACKUP 只接收 VRRP 数据,不发送数据,如果一定时间内没有接收到 MASTER 的通告信息,各 BACKUP 将宣告自己成为 MASTER,发送通告信息,重新进行 MASTER 选举状态。
高可用集群搭建
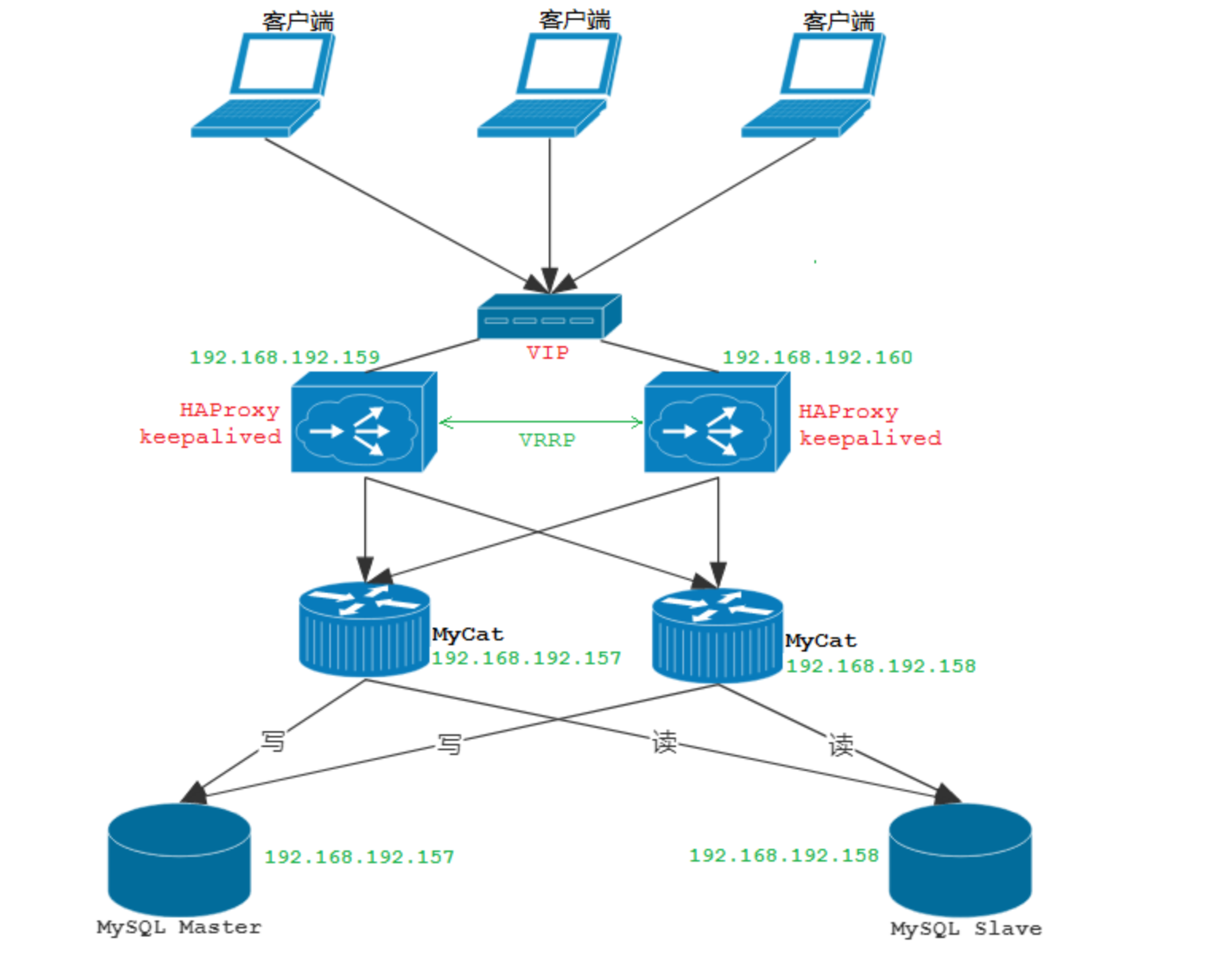
部署环境规划
| 名称 | IP | 端口 | 用户名/密码 |
|---|---|---|---|
| MySQL Master | 192.168.192.157 | 3306 | root/123456 |
| MySQL Slave | 192.168.192.158 | 3306 | root/123456 |
| MyCat节点1 | 192.168.192.157 | 8066 | root/123456 |
| MyCat节点2 | 192.168.192.158 | 8066 | root/123456 |
| HAProxy节点1/keepalived主 | 192.168.192.159 | ||
| HAProxy节点2/keepalived备 | 192.168.192.160 |
MySQL主从复制搭建
环境搭建之前需要每台服务器上都已经安装MySQL。
master
- 在master 的配置文件(/usr/my.cnf)中,配置如下内容:
1 | #mysql 服务ID,保证整个集群环境中唯一 |
- 执行完毕之后,需要重启MySQL:
1 | service mysql restart ; |
- 创建同步数据的账户,并且进行授权操作:
1 | grant replication slave on *.* to 'itcast'@'%' identified by '123456; |
- 查看master状态:
1 | show master status; |

字段含义:
1 | File : 从哪个日志文件开始推送日志文件 |
slave
- 在 slave 端配置文件中,配置如下内容:
1 | #mysql服务端ID,唯一 |
- 执行完毕之后,需要重启MySQL:
1 | service mysql restart; |
- 执行如下指令 :
1 | #指定当前从库对应的主库的IP地址,用户名,密码,从哪个日志文件开始的那个位置开始同步推送日志。 |
但是如果之前节点之间有主从复制关系,需要先停止两者的联系:
1 | stop slave; |
- 开启同步操作:
1 | start slave; |
测试验证
1 | create database db01; |
在主节点以及从节点上都可以查到数据:

MyCat安装配置
schema.xml
1 |
|
server.xml
1 | <user name="root" defaultAccount="true"> |
两台服务器均需要安装MyCat(依赖JDK)、JDK,并且MyCat服务做相同的配置 。MyCat、JDK安装见本博客的MyCat入门文档。
测试验证
两台服务器均启动MyCat:
1
2bin/mycat start;
mysql -h 192.168.192.157/8 -P 8066 -u root -p;通过查看日志验证环境是否搭建成功(记得修改日志级别为:DEBUG):
1
2select * from user;
insert into user(id,name,sex) values(null,'Tom2','1');

读操作走从节点,写操作走主节点。
HAProxy安装配置
安装
- 准备好HAProxy安装包,分别上传到两台服务器(192.168.192.159/160都安装)的/root目录下:
1 | haproxy-1.5.16.tar.gz |
- 解压到/usr/local/src目录下:
1 | tar -zxvf haproxy-1.5.16.tar.gz -C /usr/local/src |
- 进入解压后的目录,查看内核版本,进行编译:
1 | cd /usr/local/src/haproxy-1.5.16 |
- 编译完成后,进行安装:
1 | make install PREFIX=/usr/local/haproxy |
- 安装完成后,创建目录:
1 | mkdir -p /usr/data/haproxy/ |
- 创建HAProxy配置文件:
1 | vim /usr/local/haproxy/haproxy.conf |
1 | global |
内容解析如下 :
1 | #global 配置中的参数为进程级别的参数,通常与其运行的操作系统有关 |
HAProxy的负载均衡策略:
| 策略 | 含义 |
|---|---|
| roundrobin | 表示简单的轮循,即客户端每访问一次,请求轮循跳转到后端不同的节点机器上 |
| static-rr | 基于权重轮循,根据权重轮循调度到后端不同节点 |
| leastconn | 加权最少连接,表示最少连接者优先处理 |
| source | 表示根据请求源IP,这个跟Nginx的IP_hash机制类似,使用其作为解决session问题的一种方法 |
| uri | 表示根据请求的URL,调度到后端不同的服务器 |
| url_param | 表示根据请求的URL参数来进行调度 |
| hdr(name) | 表示根据HTTP请求头来锁定每一次HTTP请求 |
| rdp-cookie(name) | 表示根据cookie(name)来锁定并哈希每一次TCP请求 |
启动访问
- 启动HAProxy:
1 | /usr/local/haproxy/sbin/haproxy -f /usr/local/haproxy/haproxy.conf |
- 查看HAProxy进程:
1 | ps -ef|grep haproxy |

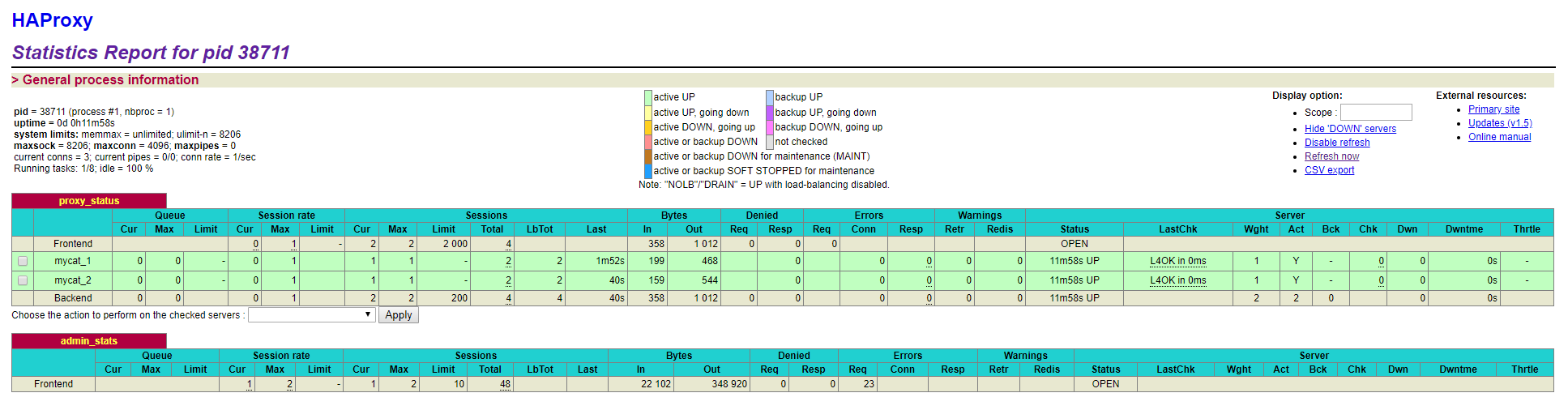
- 访问
http://192.168.192.159:8888/admin
界面:
Keepalived安装配置
Keepalived之间维持一个心跳,如果与VIP绑定的Keepalived挂掉,则另外一台Keepalived立刻获得VIP绑定,执行请求分发功能。
当位于绑定VIP的Keepalived上的HAProxy挂掉后,Keepalived无法执行分发功能,但是另外一台的Keepalived仍然可以监控到该Keepalived存活,不能获得VIP绑定,这时这台Keepalived会试图重启HAProxy,如果启动不成功,Keepalived的脚本文件会将自己挂掉(自杀),之后另外一台Keepalived会立刻与VIP绑定,执行请求分发功能。
安装配置
在两台服务器上均安装HAProxy(159/160),并进行配置。
- 上传安装包到Linux:
1 | alt + p --------> put D:/tmp/keepalived-1.4.5.tar.gz |
- 解压安装包到目录 /usr/local/src:
1 | tar -zxvf keepalived-1.4.5.tar.gz -C /usr/local/src |
- 安装依赖插件:
1 | yum install -y gcc openssl-devel popt-devel |
- 进入解压后的目录,进行配置和编译:
1 | cd /usr/local/src/keepalived-1.4.5 |
- 进行编译,完成后进行安装:
1 | make && make install |
- 运行前配置:
1 | cp /usr/local/src/keepalived-1.4.5/keepalived/etc/init.d/keepalived /etc/init.d/ |
- 修改配置文件 /etc/keepalived/keepalived.conf:
- Master: 192.168.192.159
1 | global_defs { |
- BackUP: 1921.68.192.160
1 | global_defs { |
- 编写检测haproxy的shell脚本 在/etc/keepalived/haproxy_check.sh, haproxy_check.sh:
1 | !/bin/bash |
启动测试
- 启动Keepalived:
1 | service keepalived start |
- 登录验证:
1 | mysql -uroot -p123456 -h 192.168.192.200 -P 48066 |
上面语句其实也是访问HAProxy,进而访问到MySQL中的数据信息。
当主节点挂掉之后,备用节点与VIP进行绑定,而当主节点重新启用后,主节点重新与VIP进行绑定,而备用节点仍然是备用节点。
要想知道VIP与哪台服务器绑定可以使用:
1 | arp -a 地址 |
MyCat架构剖析
MyCat总体架构介绍
源码下载及导入
导入编辑器:
总体架构
MyCat在逻辑上由几个模块组成:通信协议、路由解析、结果集处理、数据库连接、监控等模块。如图所示:
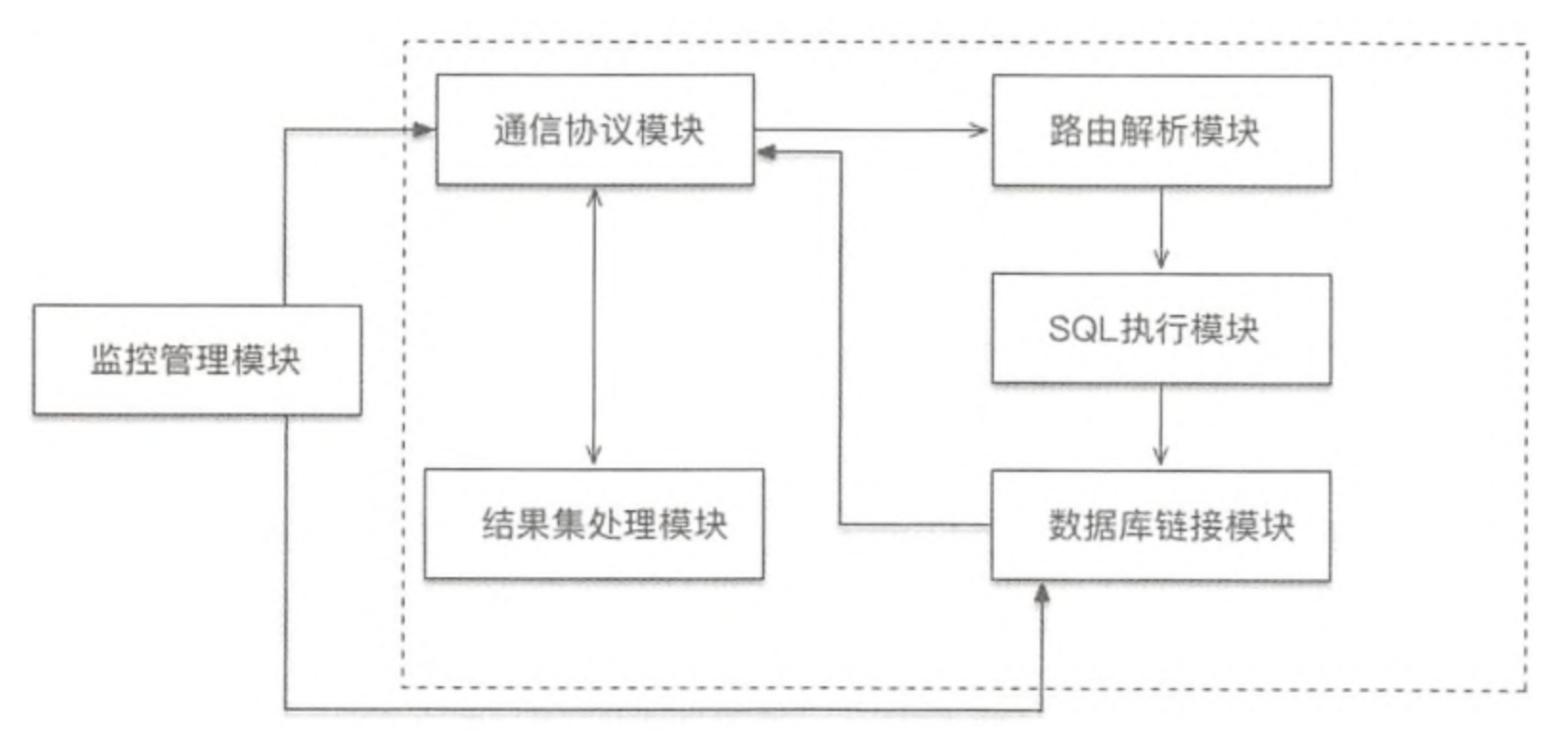
通信协议模块: 通信协议模块承担底层的收发数据、线程回调处理工作, MyCat通信协议默认采用Reactor模式,在协议层采用MySQL协议;
路由解析模块:负责对传入的SQL语句进行语法解析,解析语句的条件、类型、关键字等,并进行优化;
SQL执行模块:负责从连接池中获取连接,再根据路由解析的结果,把SQL语句分发到相应的节点执行;
数据库链接模块:负责创建、管理、维护后端的连接池。为减少每次建立数据库连接的开销,数据库使用连接池机制对连接声明周期进行管理;
结果集处理模块:负责对跨分片的查询结果进行汇聚、排序、截取等;
监控管理模块:负责MyCat的连接、内存等资源进行监控和管理。监控主要通过管理指令及监控服务展现一些监控数据; 管理则主要通过轮询事件来检测和释放不适用的资源。
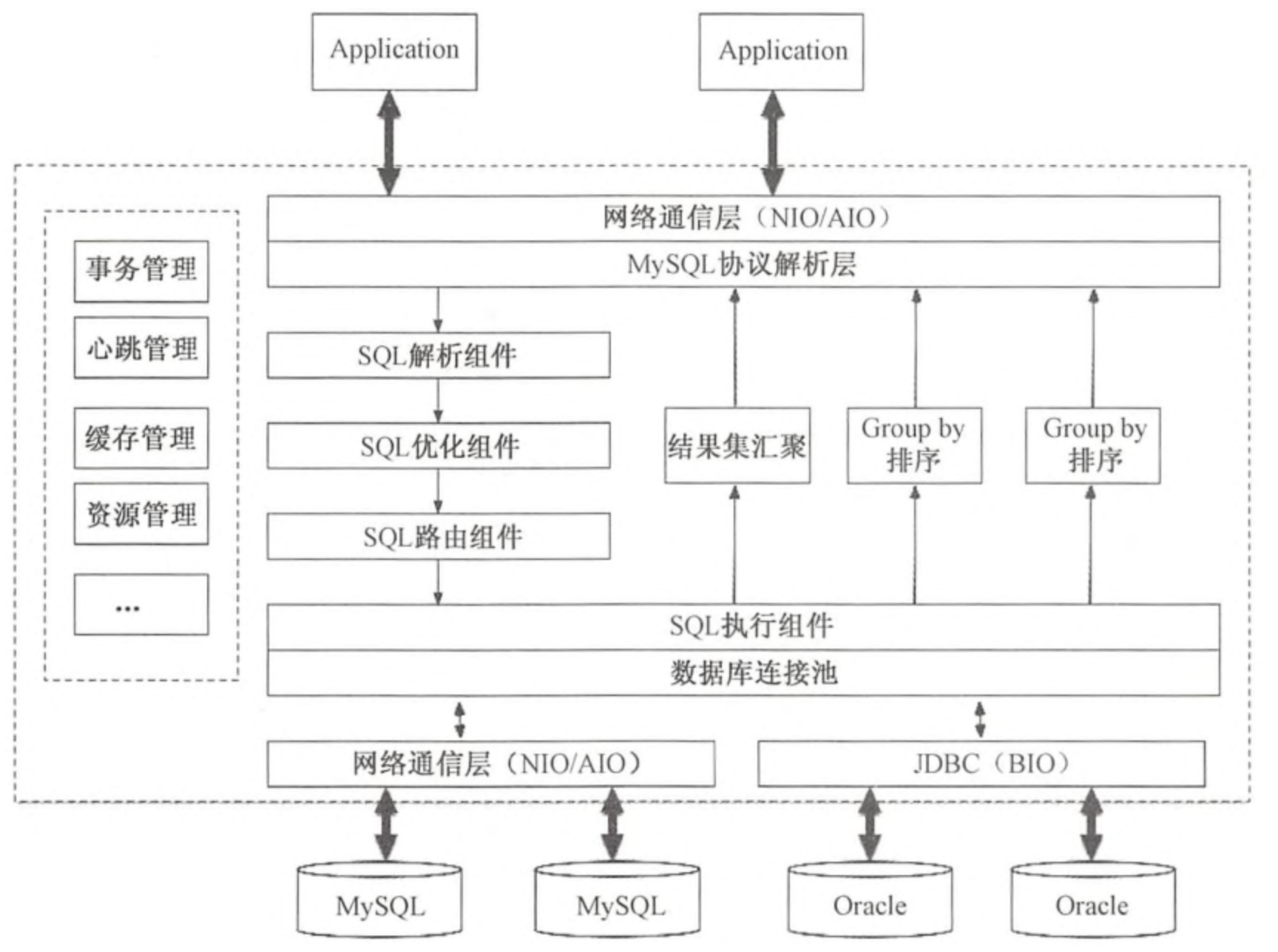
总体执行流程
MyCat网络I/O架构及实现
BIO、NIO与AIO
- BIO
BIO(同步阻塞I/O) 通常由一个单独的Acceptor线程负责监听客户端的连接,接收到客户端的连接请求后,会为每个客户端创建一个新的线程进行处理,处理完成之后,再给客户端返回结果,销毁线程 。
每个客户端请求接入时,都需要开启一个线程进行处理,一个线程只能处理一个客户端连接。 当客户端变多时,会创建大量的处理线程,每个线程都需要分配栈空间和CPU,并且频繁的线程上下文切换也会造成性能的浪费,所以该模式无法满足高性能、高并发接入的需求。
- NIO
NIO(同步非阻塞I/O)基于Reactor模式作为底层通信模型,Reactor模式可以将事件驱动的应用进行事件分派,将客户端发送过来的服务请求分派给合适的处理类(handler)。当Socket有流可读或可写入Socket时,操作系统会通知相应的应用程序进行处理,应用程序再将流读取到缓冲区或写入操作系统。这时已经不是一个连接对应一个处理线程了,而是一个有效的请求对应一个线程,当没有数据时,就没有工作线程来处理。
NIO 的最大优点体现在线程轮询访问Selector,当read或write到达时则处,未到达时则继续轮询。
- AIO
AIO是全程 Asynchronous IO(异步非阻塞的IO),是一种非阻塞异步的通信模式。在NIO的基础上引入了新的异步通道的概念,并提供了异步文件通道和异步套接字通道的实现。AIO中客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理。
AIO与NIO的主要区别在于回调与轮询,客户端不需要关注服务处理事件是否完成,也不需要轮询,只需要关注自己的回调函数。
通信架构
在MyCat中实现了NIO与AIO两种I/O模式,可以通过配置文件server.xml进行指定 :
1 | <property name="usingAIO">1</property> |
usingAIO为1代表使用AIO模型,为0表示使用NIO模型。
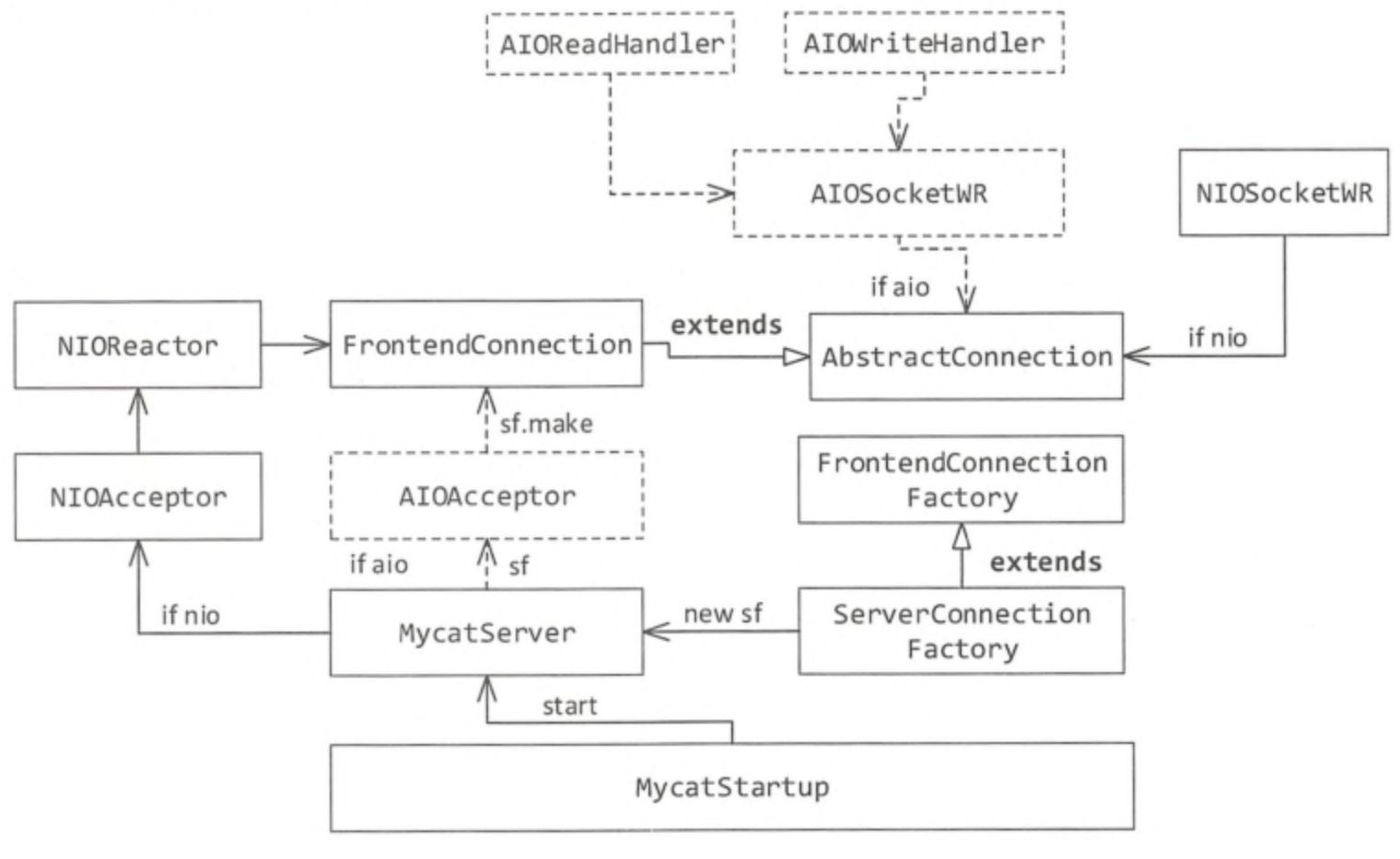
MyCat的AIO架构
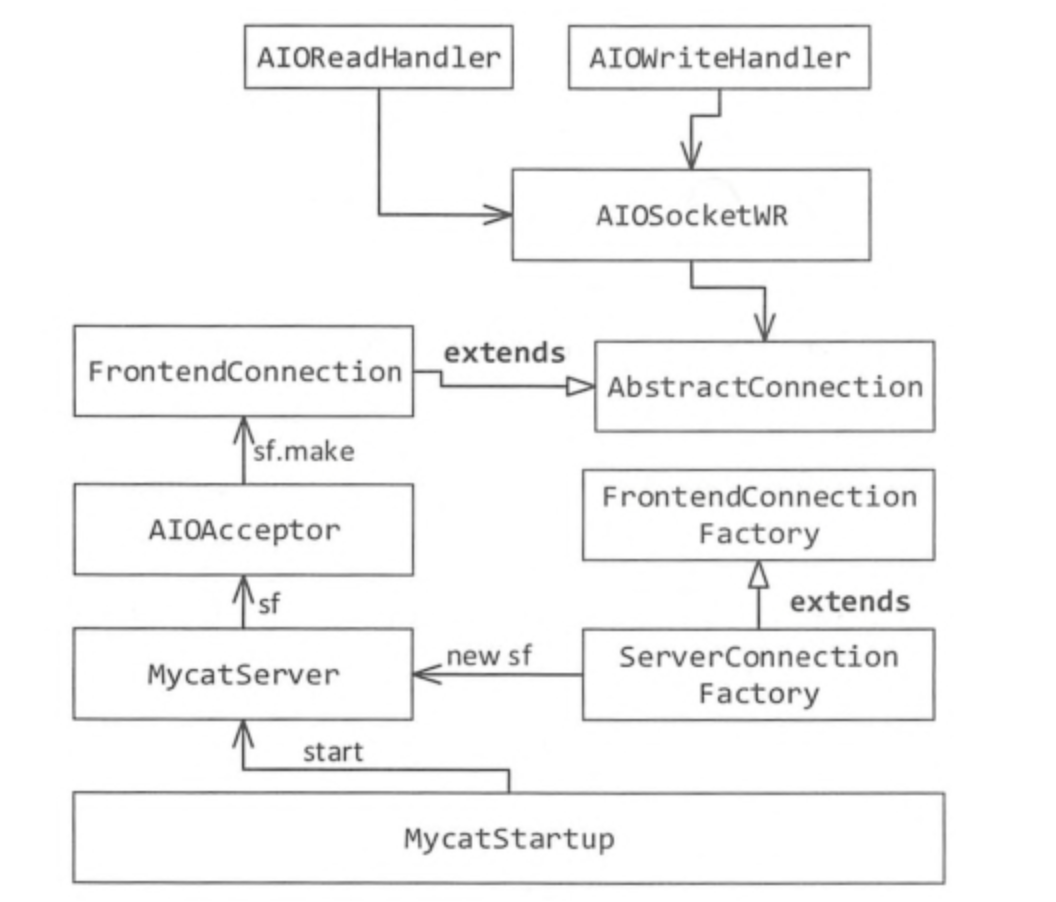
MyCatStartUp是整个MyCat服务启动的入口;
在获取到MyCat的home目录后,把主要的任务交给MyCatServer,并调用其startup方法;
初始化系统配置,获取配置文件中的usingAIO的配置,如果配置为1,说明使用AIO模型,进入到AIO的分支,并创建两个连接,一个是管理后台连接(9066),一个server的连接(8066);
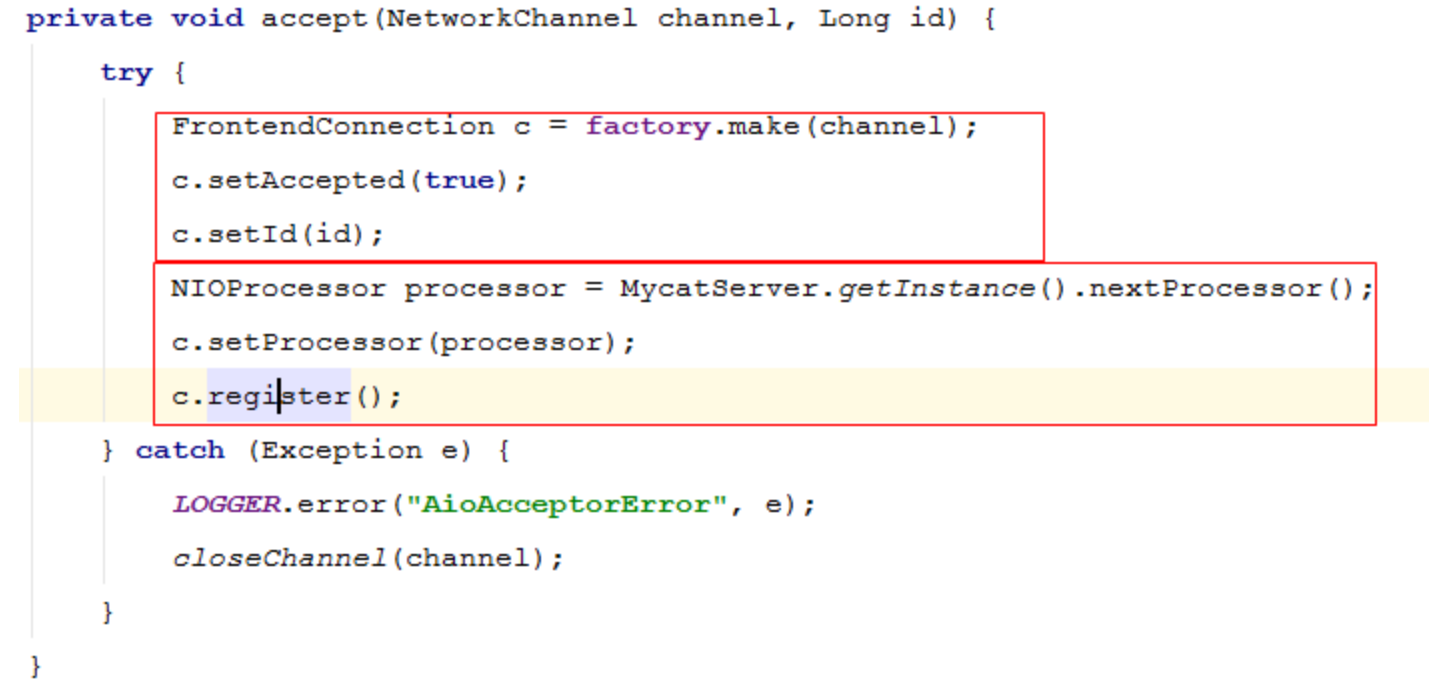
进入AIO分支,主要有AIOAcceptor接收客户端请求,绑定端口,创建服务端的异步Socket;在accept方法中完成两件事: ①FrontedConnection的创建,这是前段连接的关键; ② register注册事件,MySQL协议握手包就在此时发送。
AIOAcceptor的accept方法 :
MyCat的NIO架构
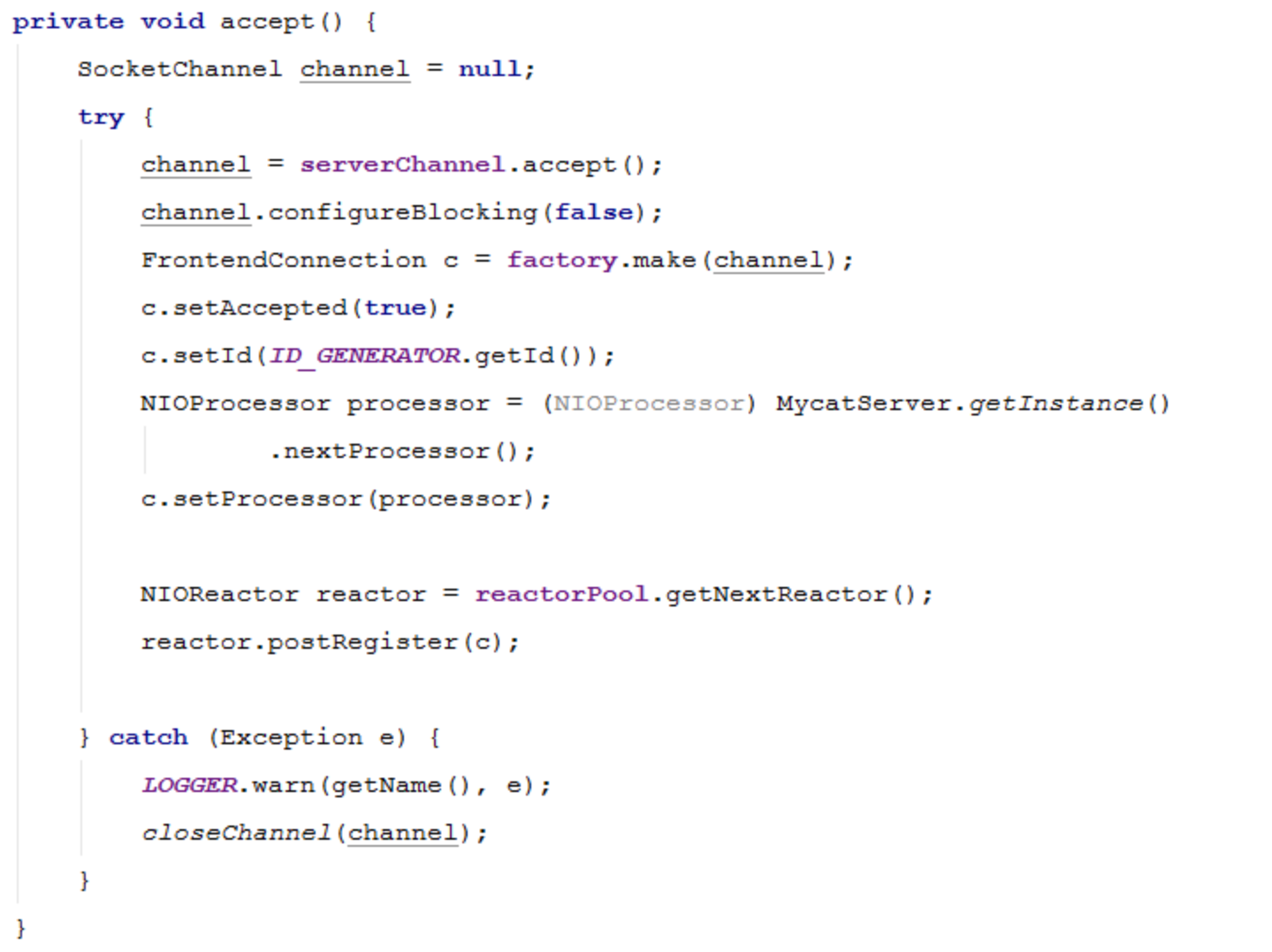
如果设置的usingAIO为0,那么将走NIOAcceptor通道,流程如下:
如果走NIO分支,将首先创建NIOAcceptor对象,并调用其start方法;
NIOAcceptor 负责处理Accept事件,服务端接收客户端的连接事件,就是MyCat作为服务端去处理前端业务程序发过来的连接请求, 建立连接后,调用NIOAcceptor的NIOReactor.postRegister方法进行注册(并没有注解注册,而是放入缓冲队列,避免加锁的竞争)。
NIOAcceptor的accept方法 :
Mycat实现MySQL协议
MySQL协议简介
概述
MySQL协议处于应用层之下、TCP/IP之上,在MySQL客户端和服务端之间使用。包含了链接器、MySQL代理、主从复制服务器之间通信,并支持SSL加密、传输数据的压缩、连接和身份验证及数据交互等。其中,握手认证阶段和命令执行阶段是MySQL协议中的两个重要阶段。
握手认证阶段
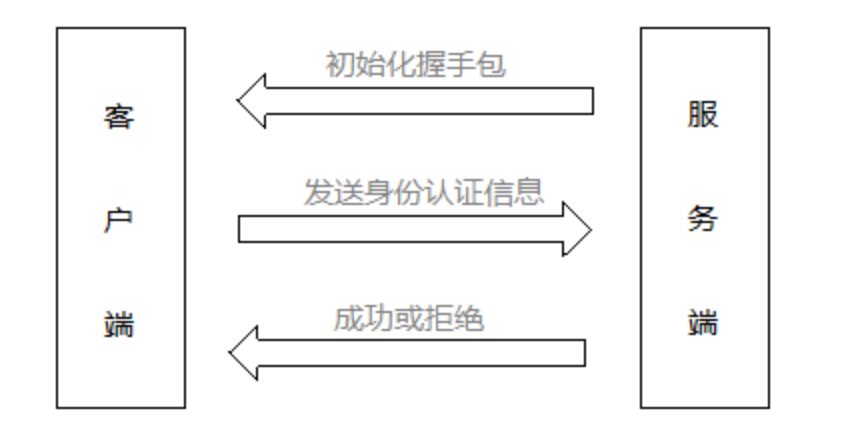
握手认证阶段是客户端连接服务器的必经之路,客户端与服务端完成TCP的三次握手以后,服务端会向客户端发送一个初始化握手包,握手包中包含了协议版本、MySQLServer版本、线程ID、服务器的权能标识和字符集等信息。
客户端在接收到服务端的初始化握手包之后,会发送身份验证包给服务端(AuthPacket),该包中包含用户名、密码等信息。
服务端接收到客户端的登录验证包之后,需要进行逻辑校验,校验该登录信息是否正确。如果信息都符合,则返回一个OKPacket,表示登录成功,否则返回ERR_Packet,表示拒绝。
Wireshark抓包如下:

报文分析如下:
- 初始化握手包:
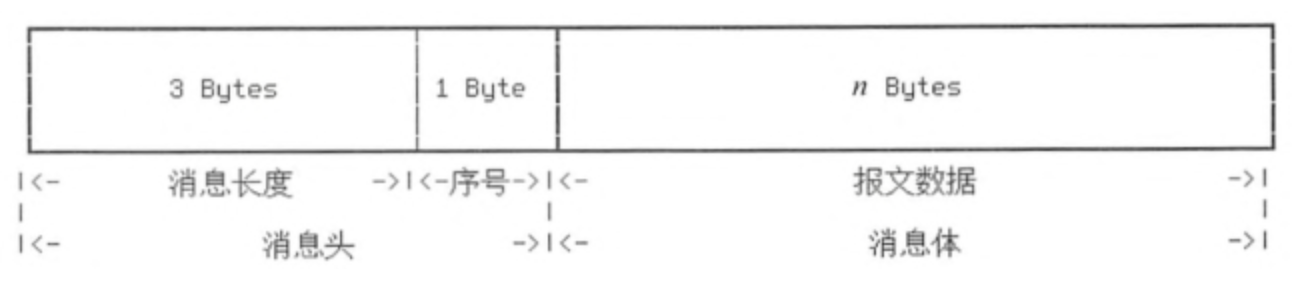
通过抓包工具Wireshark抓取到的握手包信息如下:
说明:
Packet Length:包的长度
Packet Number:包的序号
Server Greeting:消息体,包含了协议版本、MySQLServer版本、线程ID和字符集等信息。
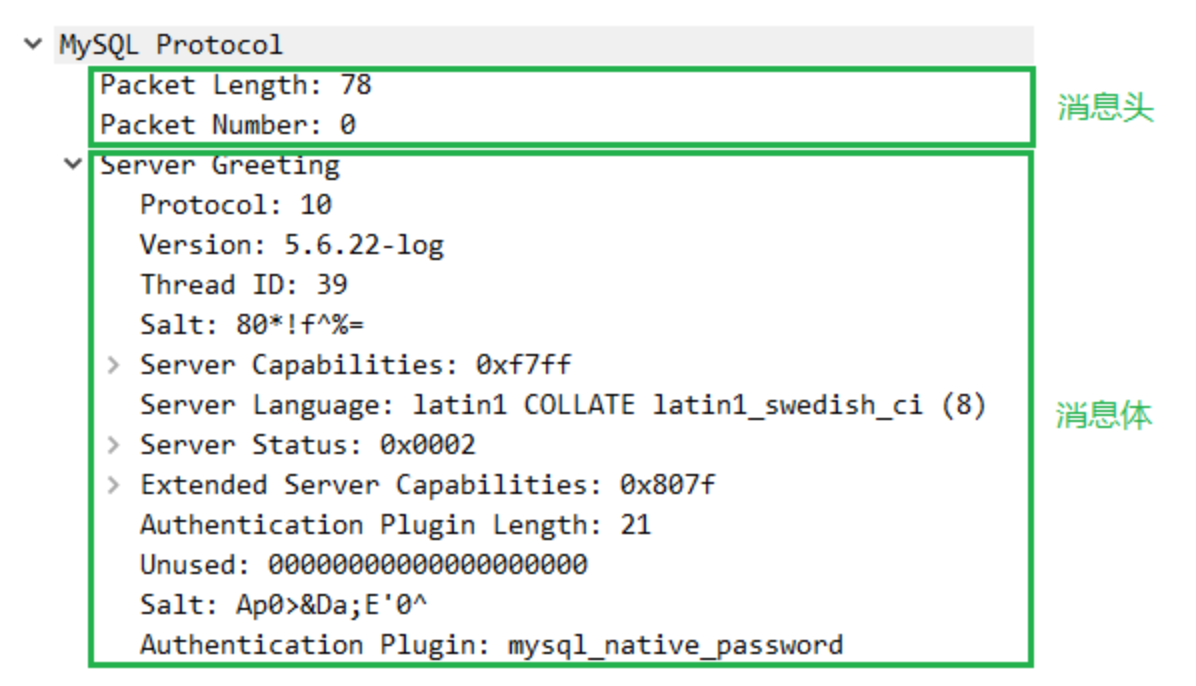
- 登录认证包
客户端在接收到服务端发来的初始握手包之后,向服务端发出认证请求,该请求包含以下信息(由Wireshark抓获):
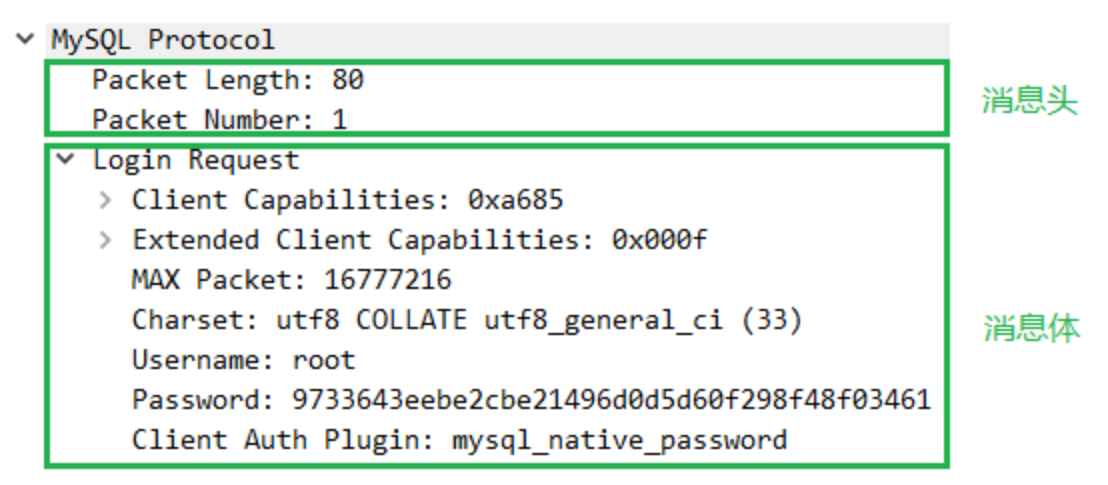
- OK包或ERROR包
服务端接收到客户端的登录认证包之后,如果通过认证,则返回一个OKPacket,如果未通过认证,则返回一个ERROR包。
OK报文如下:
ERROR报文如下:

命令执行阶段
在握手认证阶段通过并完成以后,客户端可以向服务端发送各种命令来请求数据,此阶段的流程是:命令请求->返回结果集。
Wireshark 捕获的数据包如下:

- 命令包:
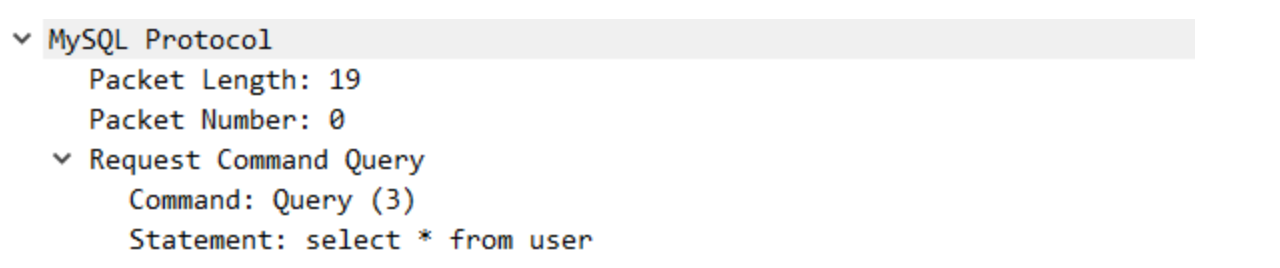
- 结果集包:
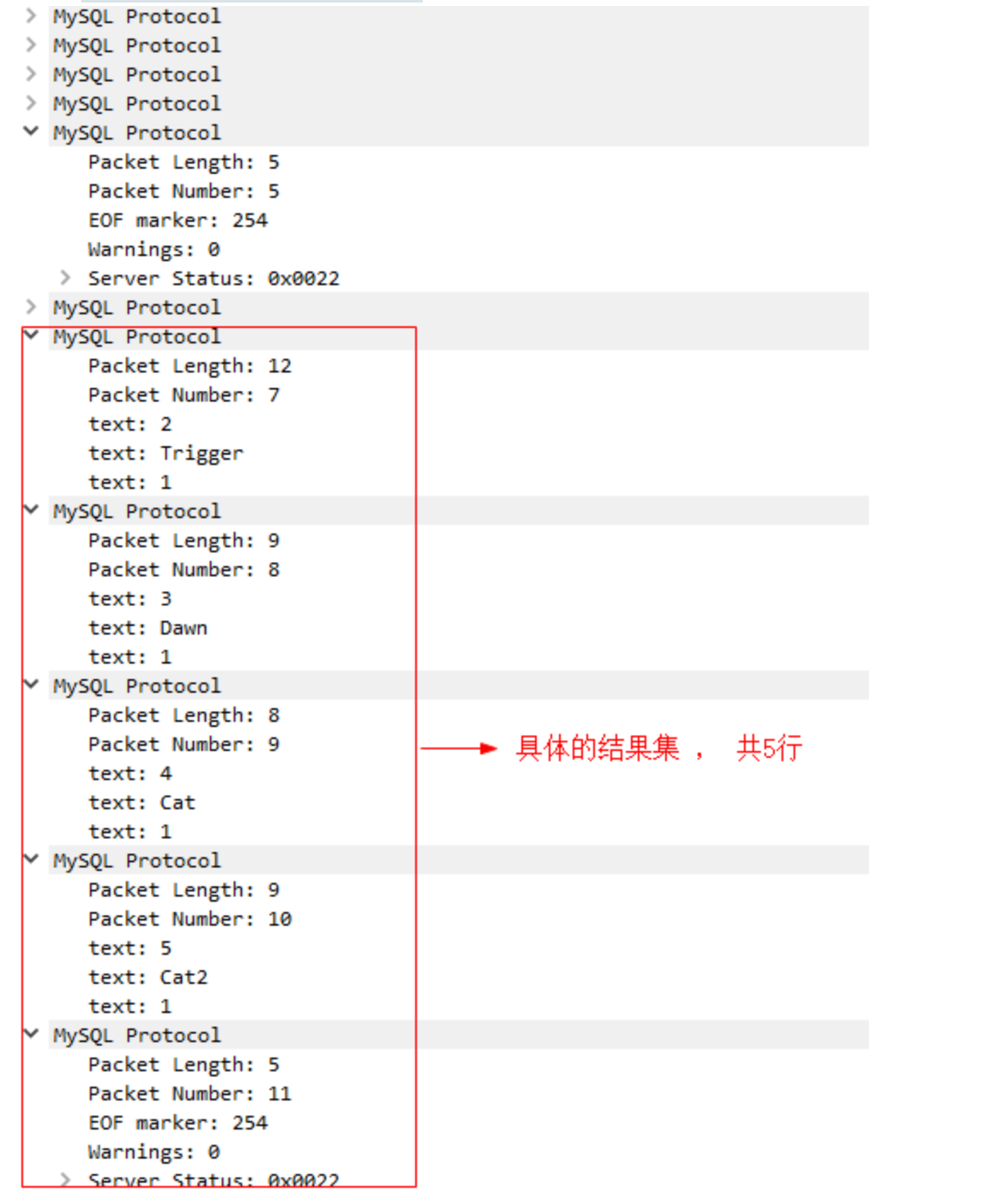
MySQL协议在MyCat中实现
握手认证实现
在MyCat中同时实现了NIO和AIO,通过配置可以选择NIO和AIO。MyCat Server在启动阶段已经选择好采用NIO还是AIO,因此建立I/O通道后,MyCat服务端一直等待客户端的连接,当有连接到来的时候,MyCat首先发送握手包。
- 握手包源码实现:MyCat源码中io.mycat.net.FrontendConnection类的实现如下:

握手包信息组装完毕后,通过FrontedConnection写回客户端。
- 认证包源码实现
客户端接收到握手包后,紧接着向服务端发起一个认证包,MyCat封装为类 AuthPacket:
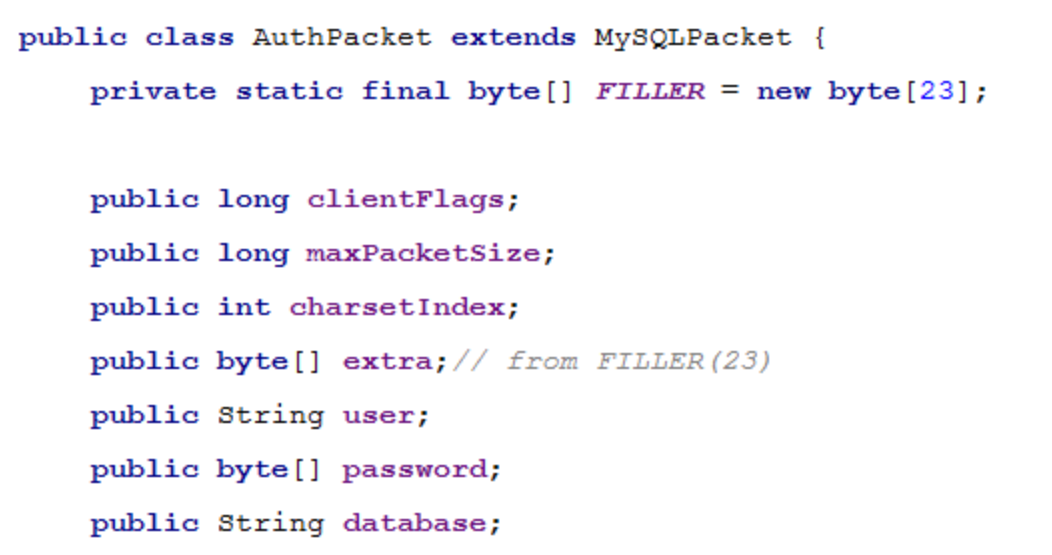
客户端发送的认证包转由 FrontendAuthenticator 的Handler来处理,主要操作就是 拆包,检查用户名、密码合法性,检查连接数是够超出限制。源码实现如下:
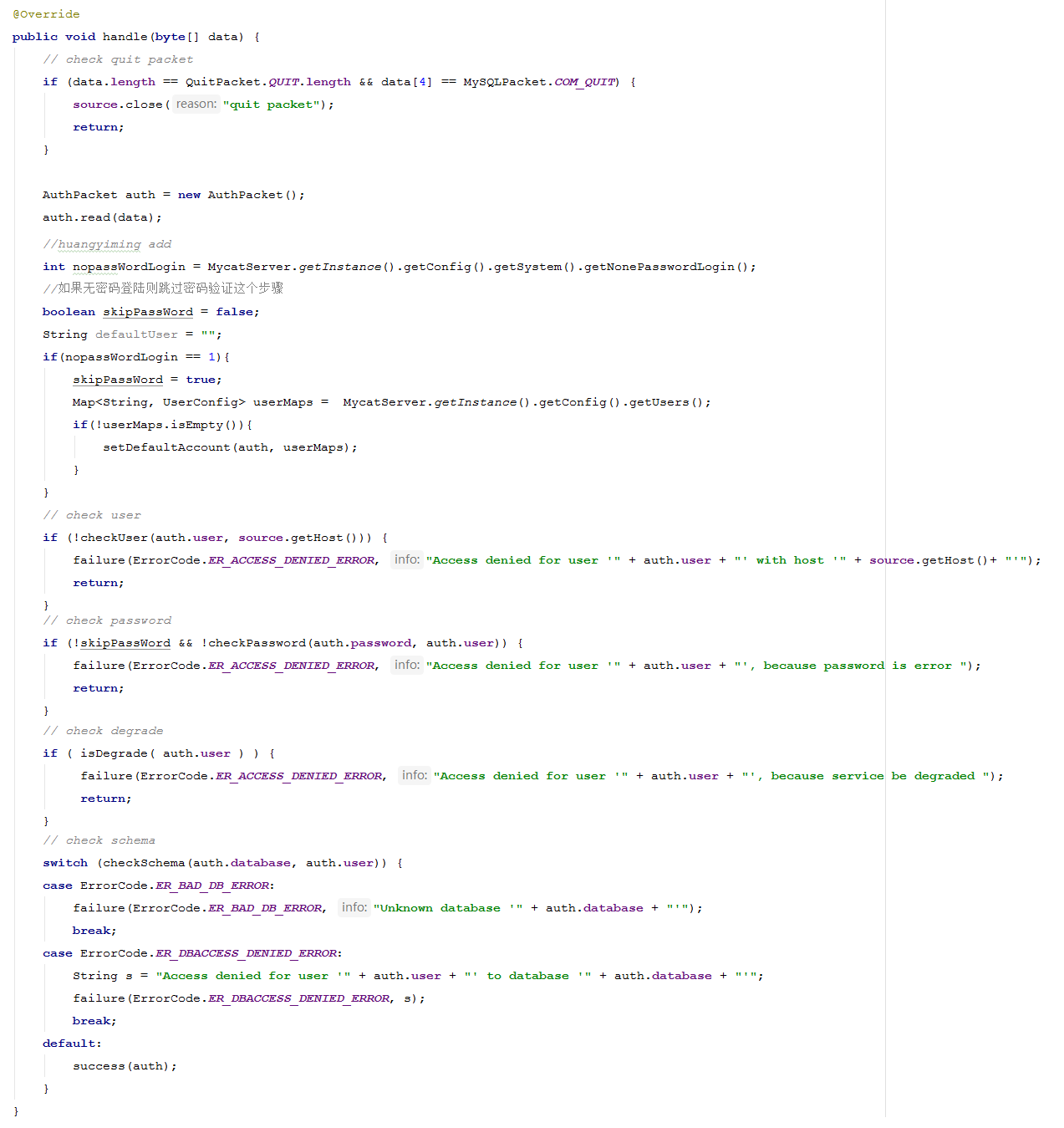
认证失败,调用failure方法,认证成功调用success方法。
failure方法源码:
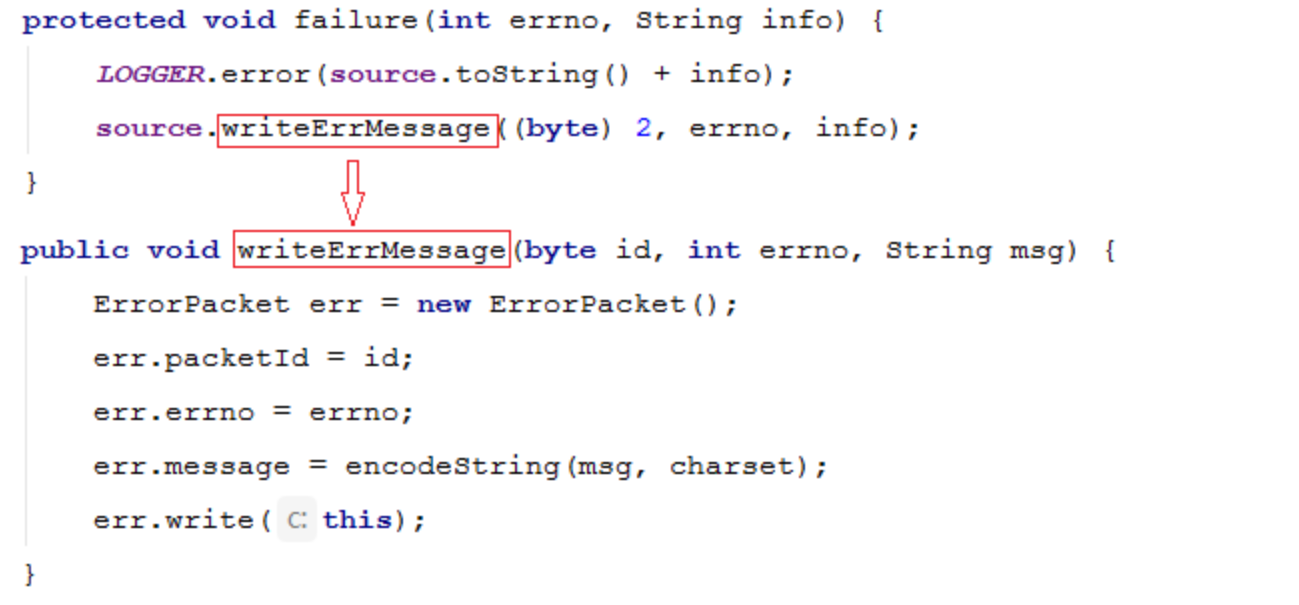
success方法源码:
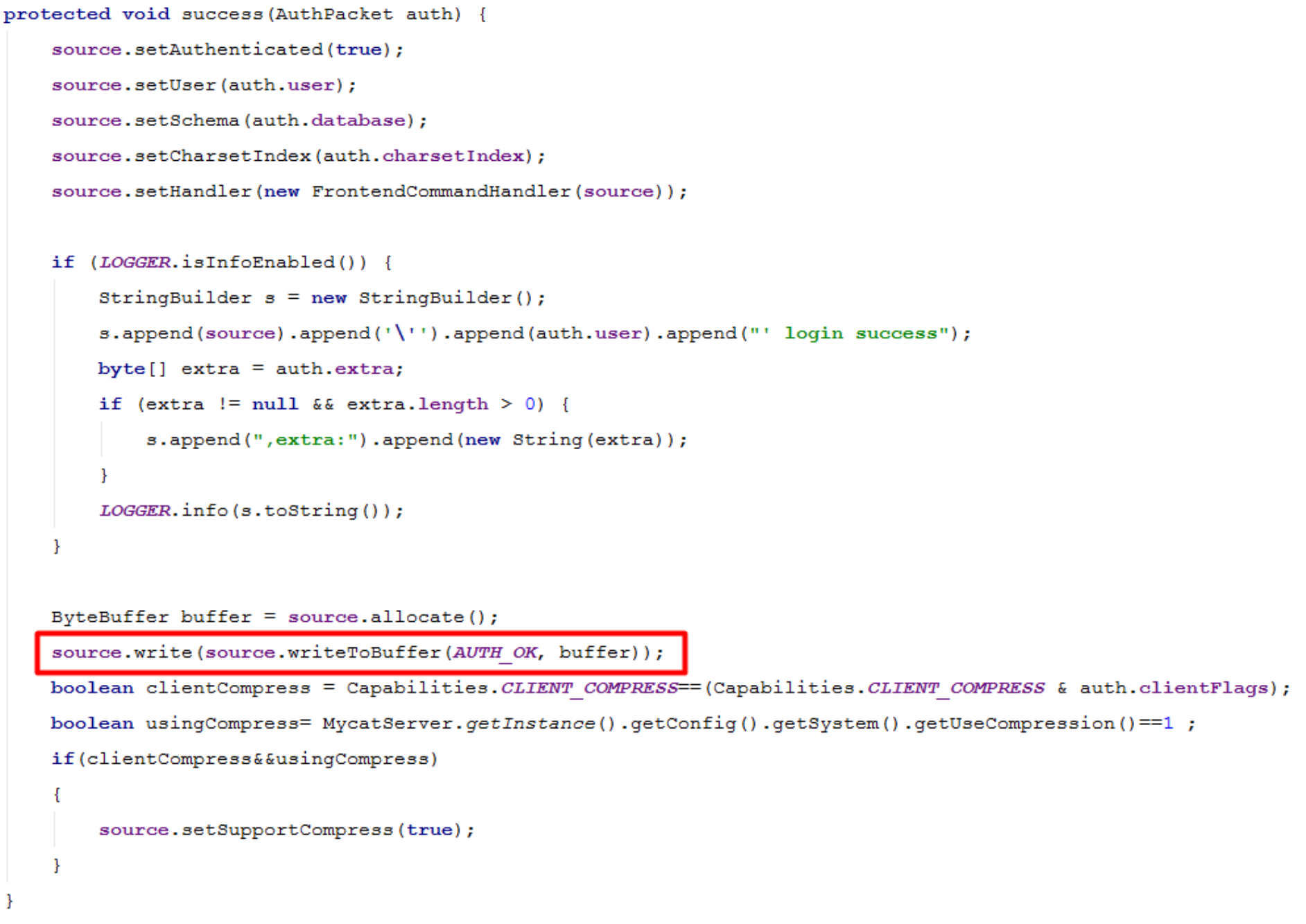
命令执行实现
命令执行阶段就是SQL命令和SQL语句执行阶段,在该阶段MyCat主要需要做的事情,就是对客户端发来的数据包进行拆包,并判断命令的类型,并解析SQL语句,执行响应的SQL语句,最后把执行结果封装在结果集包中,返回给客户端。
从客户端发来的命令交给 FrontendCommandHandler 中的handle方法处理:

处理具体的请求,返回客户端结果集数据包:

MyCat线程架构与实现
MyCat线程池实现
在MyCat中大量用到了线程池,通过线程池来避免频繁的创建和销毁线程而造成的系统性能的浪费。在MyCat中使用的线程池是JDK中提供的线程池 ThreadPoolExecutor 的子类 NameableExecutor , 构造方法如下:
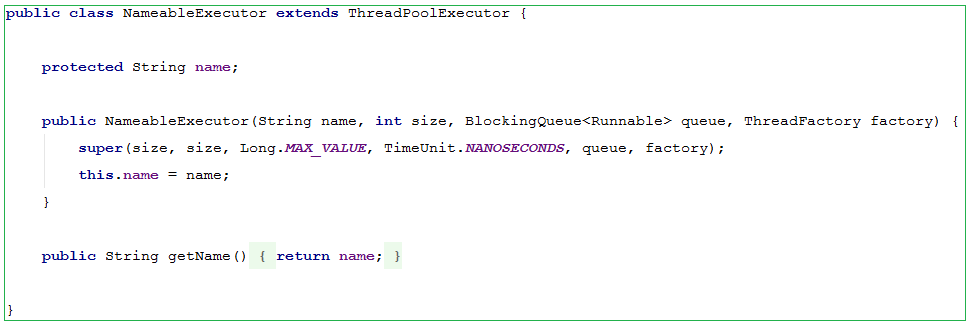
父类构造为:

构造参数含义:
corePoolSize : 核心池大小
maximumPoolSize : 最大线程数
keepAliveTime: 线程没有任务执行时,最多能够存活多久
timeUnit: 时间单位
workQueue: 阻塞任务队列
threadFactory: 线程工厂,用来创建线程
MyCat线程架构
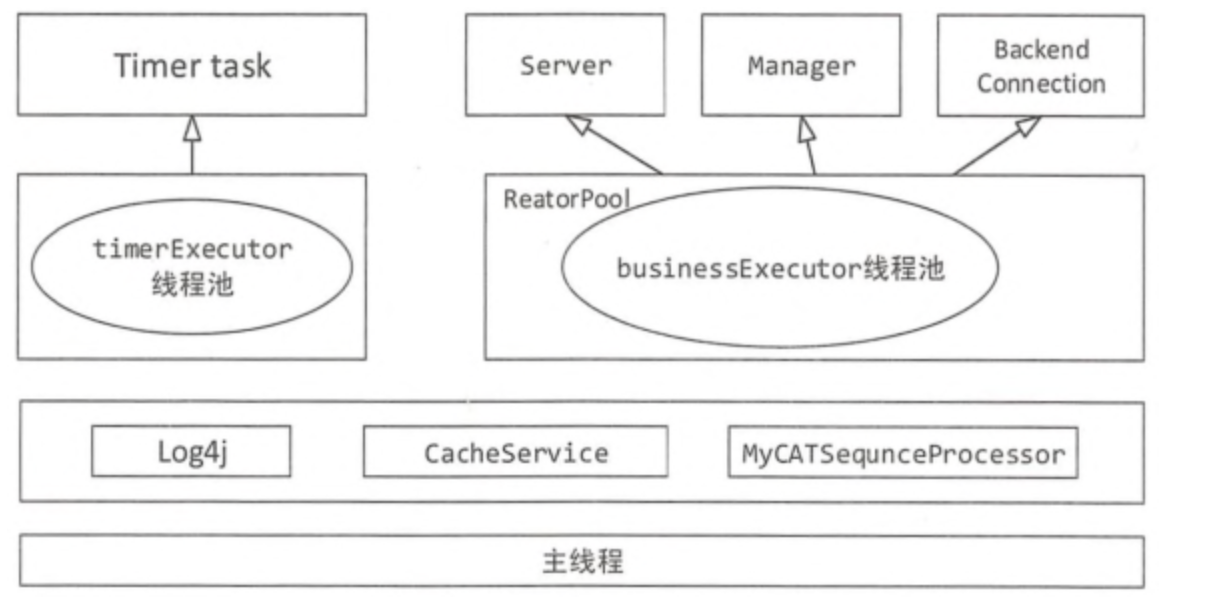
在MyCat中主要有两大线程池:timerExecutor 和 businessExecutor。
timerExecutor 线程池主要完成系统时间定时更新、处理器定时检查、数据节点定时连接、空闲超时检查、数据节点定时心跳检测等任务。
businessExecutor是MyCat最重要的线程资源池,该资源池的线程使用的范围非常广,涵盖以下方面:
- 后端用原生协议连接数据
- JDBC执行SQL语句
- SQL拦截
- 数据合并服务
- 批量SQL作业
- 查询结果的异步分发
- 基于guava实现异步回调

MyCat内存管理及缓存框架与实现
这里所提到的内存管理指的是MyCat缓冲区管理,众所周知设置缓冲区的唯一目的是提高系统的性能,缓冲区通常是部分常用的数据存放在缓冲池中以便系统直接访问,避免使用磁盘IO访问磁盘数据,从而提高性能。
内存管理
缓冲池组成:缓冲池的最小单位为chunk,默认的chunk大小为4096字节(DEFAULT_BUFFER_CHUNK_SIZE),BufferPool的总大小为4096 x processors x 1000(其中processors为处理器数量)。对I/O进程而言,他们共享一个缓冲池。缓冲池有两种类型:本地缓存线程(以$_开头的线程)缓冲区和其他缓冲区,分配buffer时,优先获取ThreadLocalPool中的buffer,没有命中时会获取BufferPool中的buffer。
分配MyCat缓冲池:分配缓冲池时,可以指定大小,也可以用默认值。
- allocate():先检测是否为本地线程,当执行线程为本地缓存线程时,localBufferPool取出一个可用的buffer。如果不是,则从ConcurrentLinkedQueue队列中取出一个buffer进行分配,如果队列没有可用的buffer,则创建一个直接缓冲区。
- allocate(size):如果用户指定的size不大于chunkSize,则调用allocate()进行分配;反之则调用createTempBuffer(size)创建临时非直接缓冲区。
- MyCat缓冲池的回收:回收时先判断buffer是否有效,有如下情况时缓冲池不回收。
- 不是直接缓冲区
- buffer是空的
- buffer的容量大于chunkSize
MyCat缓存架构
- 缓存框架选择:MyCat支持ehcache、mapdb、leveldb缓存,可通过配置文件cacheserver.properties来进行配置:
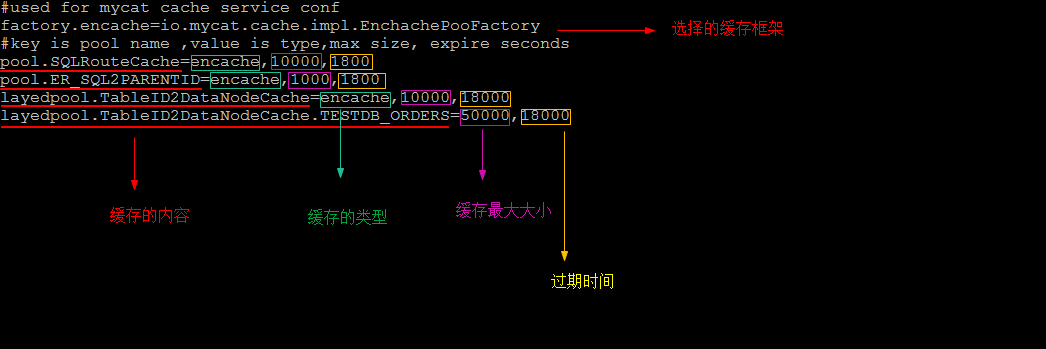
- 缓存内容:MyCat有路由缓存、表主键到datanode缓存、ER关系缓存。
- 路由缓存: 即SQLRouteCache, 根据SQL语句查找路由信息的缓存, 该缓存只是针对select语句, 如果执行了之前已经执行过的某个SQL语句(缓存命中), 那么路由信息就不需要重复计算了, 直接从缓存中获取。
- 表主键到datanode缓存: 当分片字段与主键字段不一致时, 直接通过主键值查询时无法定位具体分片的(只能全分片下发), 所以设置该缓存之后, 就可以利用主键值查找到分片名, 缓存的key是ID值, value是节点名。
- ER关系缓存: 在ER分片时使用, 而且在insert查询中才会使用缓存, 当子表插入数据时, 根据父子关联字段确定子表分片, 下次可以直接从缓存中获取所在的分片。
查看缓存指令: show @@cache;

MyCat连接池架构与实现
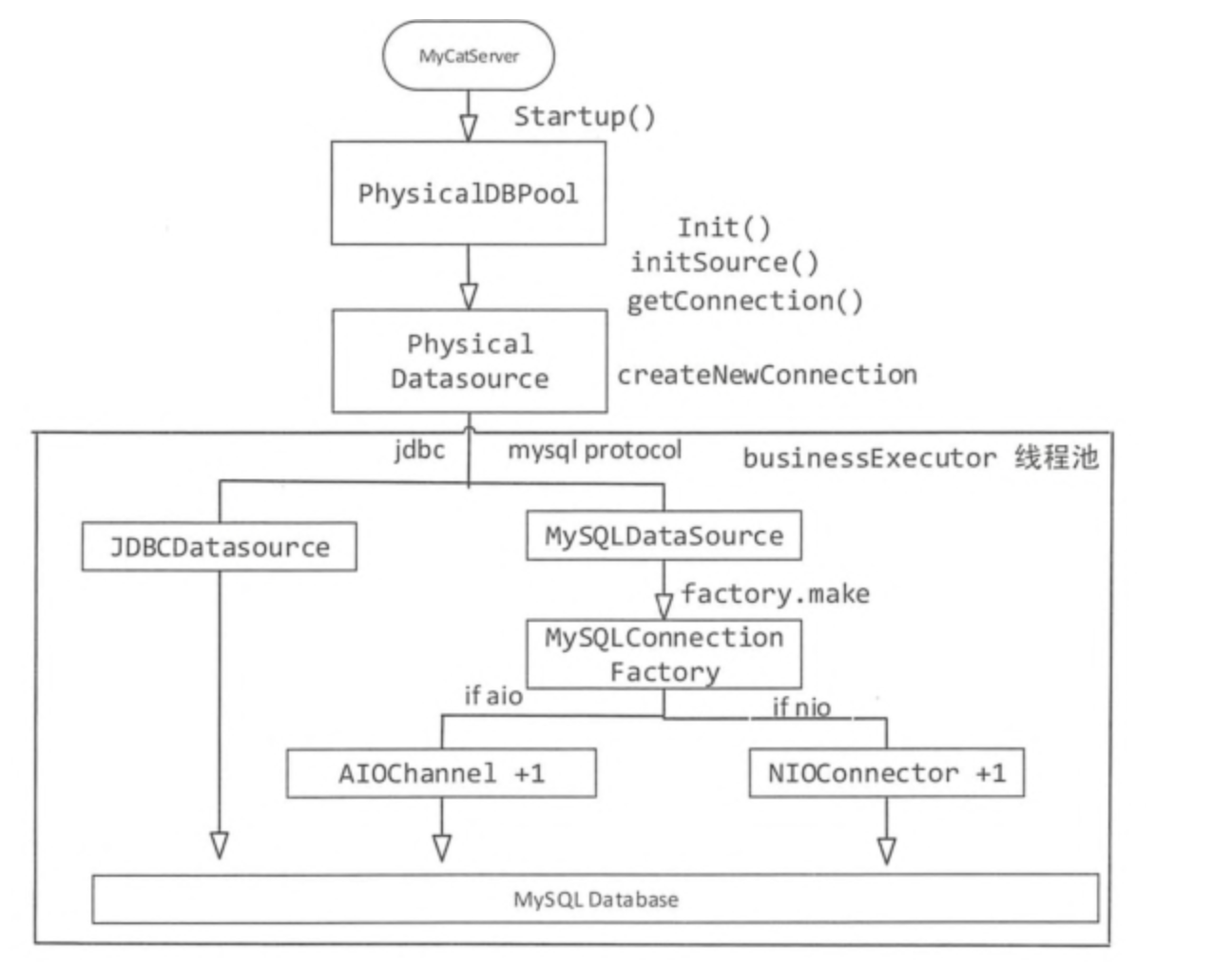
这里所讨论的连接池是MyCat的后端连接池,也就是MyCat后端与各个数据库节点之间的连接架构。
连接池创建:MyCat按照每个dataHost创建一个连接池,根据schema.xml文件的配置取得最小的连接数minCon,并初始化minCon个连接。在初始化连接时,还需要判定用户选择的是JDBC还是原生的MySQL协议,以便于创建对应的连接。
连接池分配:分配连接就是从连接池队列中取出一个连接,在取出一个连接时,MyCat需要根据负载均衡(balance属性)的类型选择不同的数据源,因为连接和数据源绑在一起,所以需要知道MyCat读写的是那些数据源,才能分配响应的连接。
架构:
MyCat主从切换架构与实现
MyCat主从切换概述
MyCat实现MySQL读写分离的目的在于降低单节点数据库的访问压力, 原理就是让主数据库执行增删改操作,从数据库执行查询操作,利用MySQL数据库的复制机制将Master的数据同步到slave上。
当master宕机后,slave承载的业务如何切换到master继续提供服务,以及slave宕机后如何将master切换到slave上。手动切换数据源很简单, 但不是运维工作的首选,本节重点就是讲解如何实现自动切换。
MyCat的读写分离依赖于MySQL的主从同步,也就是说MyCat没有实现数据的主从同步功能,但是实现了自动切换功能。
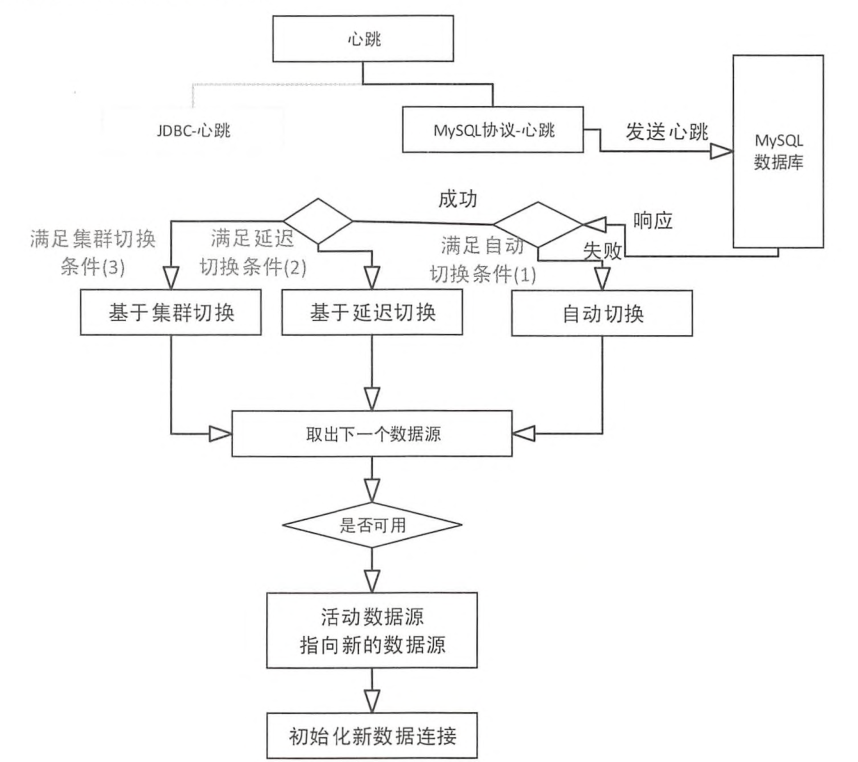
1). 自动切换
自动切换是MyCat主从复制的默认配置,当主机或从机宕机后,MyCat自动切换到可用的服务器上。假设写服务器为M,读服务器为S, 则:
正常时,写M读S;
当M宕机后,读写S;恢复M后,写S,读M;
当S宕机后,读写M;恢复S后,写M,读S 。
2). 基于MySQL主从同步状态的切换
这种切换方式与自动切换不同,MyCat检测到主从数据同步延迟时,会自动切换到拥有最新数据的MySQL服务器上,防止读到很久以前的数据。
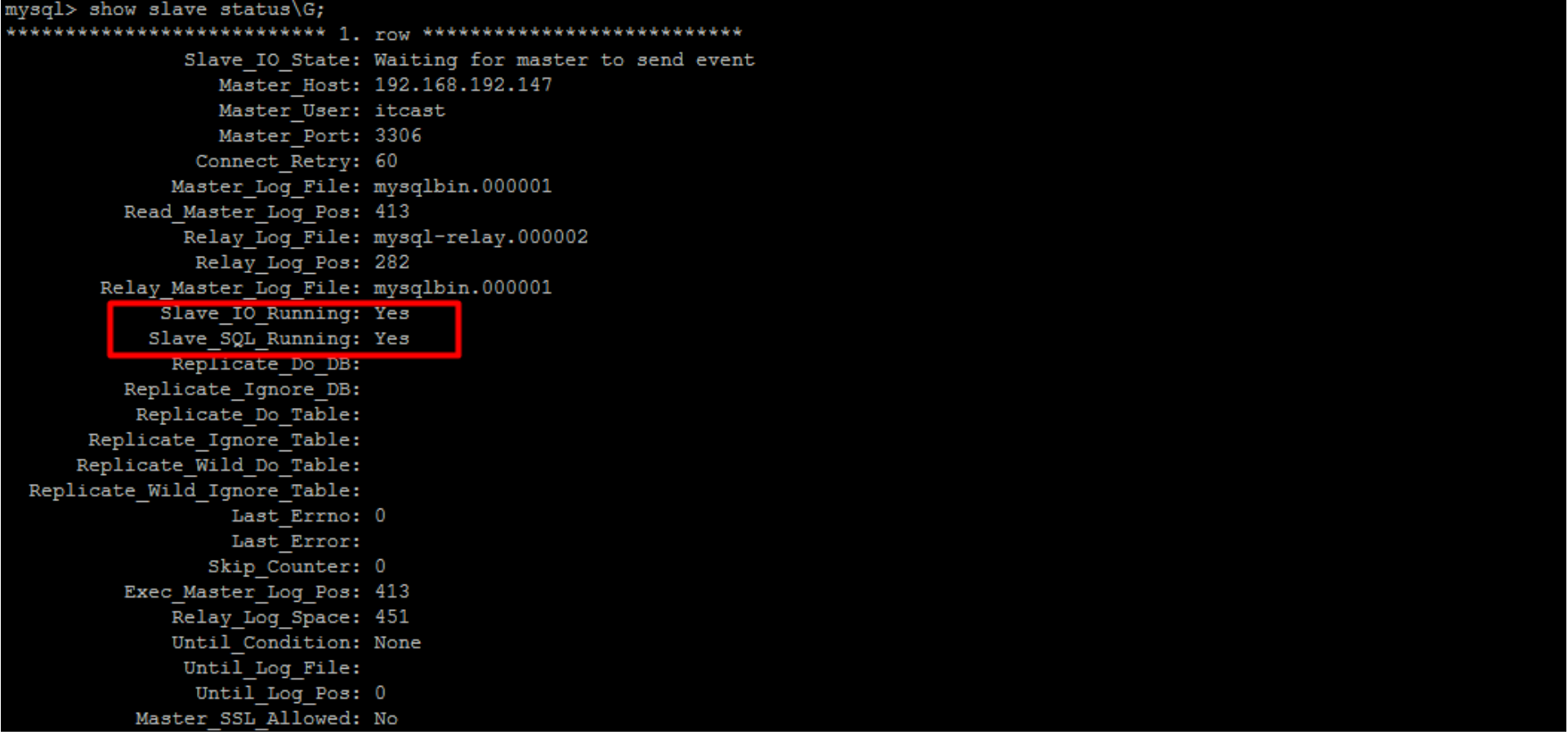
原理就是通过检查MySQL的主从同步状态(show slave status)中的Seconds_Behind_Master、Slave_IO_Running、Slave_SQL_Running三个字段,来确定当前主从同步的状态以及主从之间的数据延迟。 Seconds_Behind_Master为0表示没有延迟,数值越大,则说明延迟越高。
MyCat主从切换实现
基于延迟的切换,则判断结果集中的Slave_IO_Running、Slave_SQL_Running两个个字段是否都为yes,以及Seconds_Behind_Master 是否小于配置文件中配置的 slaveThreshold的值,如果有其中任何一个条件不满足,则切换。
主要流程如下:
MyCat核心技术
MyCat分布式事务实现
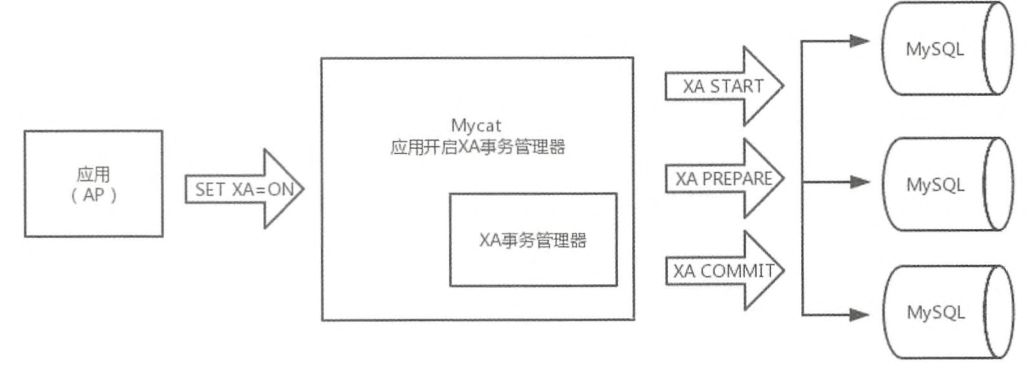
MyCat在1.6版本以后已经支持XA分布式事务类型了。具体的使用流程如下:
- 在应用层需要设置事务不能自动提交:
1 | set autocommit=0; |
- 在SQL中设置XA为开启状态:
1 | set xa = on; |
- 执行SQL:
1 | insert into user(id,name,sex) values(1,'Tom','1'),(2,'Rose','2'),(3,'Leo','1'),(4,'Lee','1'); |
- 对事务进行提交或回滚:
1 | commit/rollback |
完整流程如下:
MyCat SQL路由实现
MyCat的路由是和SQL解析组件息息相关的,SQL路由模块是MyCat数据库中间件最重要的模块之一,使用MyCat主要是为了分库分表,而分库分表的核心就是路由。
路由的作用
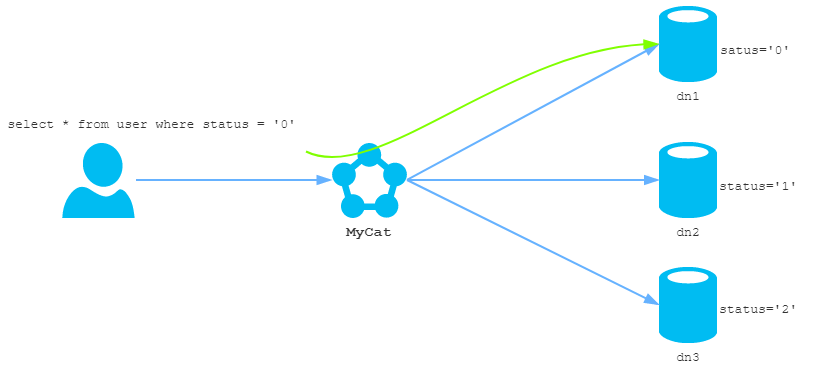
如图所示,MyCat接收到应用系统发来的查询语句,要将其发送到后端连接的MySQL数据库去执行,但是后端有三个数据库服务器,具体要查询那一台数据库服务器呢,这就是路由需要实现的功能。SQL的路由既要保证数据的完整,也不能造成资源的浪费,还要保证路由的效率。
SQL解析器
Mycat1.3版本之前模式使用的是Fdbparser的foundationdb的开源SQL解析器,在2015年被apple收购后,从开源变为闭源了。
目前版本的MyCat采用的是Druid的SQL解析器,性能比采用Fdbparser整体性能提高20%以上。
MyCat跨库Join
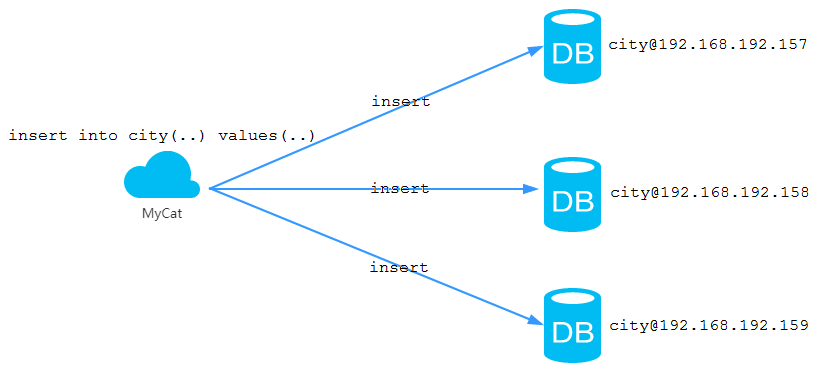
全局表
每个企业级的系统中,都会存在一些系统的基础信息表,类似于字典表、省份、城市、区域、语言表等,这些表与业务表之间存在关系, 但不是业务主从关系,而是一种属性关系。当我们对业务表进行分片处理时,可以将这些基础信息表设置为全局表,也就是在每个节点中都存在该表。
全局表的特性如下:
全局表的insert、update、delete操作会实时地在所有节点同步执行,保持各个节点数据的一致性;
全局表的查询操作会从任意节点执行,因为所有节点的数据都一致;
全局表可以和任意表进行join操作。
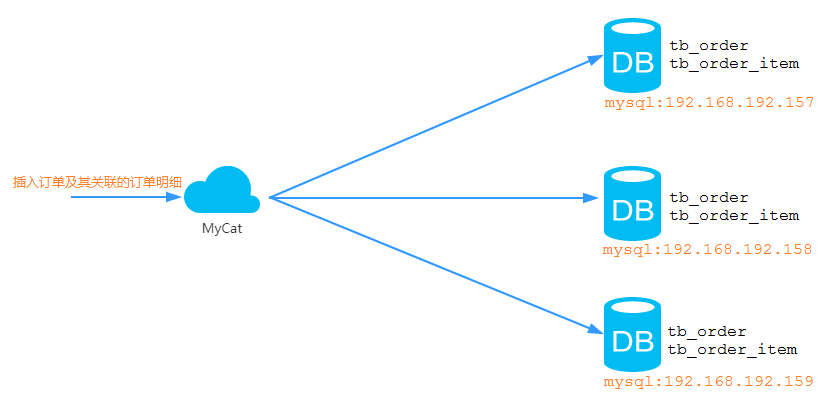
ER表
关系型数据库是基于实体关系模型(Entity Relationship Model)的,MyCat中的ER表便来源于此。MyCat提出了基于ER关系的数据分片策略,子表的记录与其所关联的父表的记录存放在同一个数据分片中,通过表分组(Table Group)保证数据关联查询不会跨库操作。
catlet
catlet是MyCat为了解决跨分片Join提出的一种创新思路,也叫做人工智能(HBT)。MyCat参考了数据库中存储过程的实现方式,提出类似的跨库解决方案,用户可以根据系统提供的API接口实现跨分片Join。采用这种方案开发时,必须要实现Catlet接口的两个方法:

route 方法:路由的方法,传递系统配置和schema配置等 ;
processSQL方法:EngineCtx执行SQL并给客户端返回结果集 。
当自定义Catlet完成之后,需要将Catlet的实现类进行编译,并将其字节码文件 XXXCatlet.class存放在mycat_home/catlet目录下,系统会加载相关Class,而且每隔1分钟扫描一次文件是否更新,若更新则自动重新加载,因此无需重启服务。
ShareJoin
ShareJoin 是Catlet的实现,是一个简单的跨分片Join,目前支持两个表的Join,原理就是解析SQL语句,拆分成单表的语句执行,单后把各个节点的数据进行汇集。要想使用Catlet完成join,还需要借助于MyCat中的注解,在执行SQL语句时,使用catlet注解:
1 | /*!mycat:catlet=demo.catlets.ShareJoin */ select a.id as aid , a.id , b.id as bid , b.name as name from customer a, company b where a.company_id=b.id and a.id = 1; |
MyCat数据汇聚与排序
通过MyCat实现数据汇聚和排序,不仅可以减少各分片与客户端之间的数据传输IO,也可以帮助开发者总复杂的数据处理中解放出来,从而专注于开发业务代码。
在MySQL中存在两种排序方式:一种利用有序索引获取有序数据,另一种通过相应的排序算法将获取到的数据在内存中进行排序。而MyCat中数据排序采用堆排序法对多个分片返回有序数据,并在合并、排序后再返回给客户端。
 微信
微信 支付宝
支付宝

