ConcurrentHashMap源码分析
ConcurrentHashMap的理解
HashMap在多线程情况下,通过put方法进行插入操作时,如果元素超过了容量(由负载因子决定)的范围就会触发扩容操作,重新将原数组的内容重新hash到新的扩容数组中。在多线程的环境下,存在同时其他的元素也在进行put操作,如果hash值相同,可能出现同时在同一数组下用链表表示时,造成闭环,导致在get时会出现死循环,此外,put的时候也可能导致多线程数据不一致,所以HashMap是线程不安全的。
HashTable是线程安全的,它在所有涉及到多线程操作的都加上了synchronized关键字来锁住整个table,这就意味着所有的线程都在竞争一把锁,在多线程的环境下,它是安全的,但是无疑是效率低下的。
其实HashTable有很多的优化空间,锁住整个table这么粗暴的方法可以变得柔和点,比如在多线程的环境下,对不同的数据集进行操作时其实根本就不需要去竞争一个锁,因为它们操作不同hash值,不会因为rehash造成线程不安全,所以互不影响,这就是锁分离技术,将锁的粒度降低,利用多个锁来控制多个小的table。
JDK1.7 ConcurrentHashMap实现原理
数据结构
在JDK1.7版本中,ConcurrentHashMap的数据结构是由一个Segment数组和多个HashEntry组成,如下图所示:
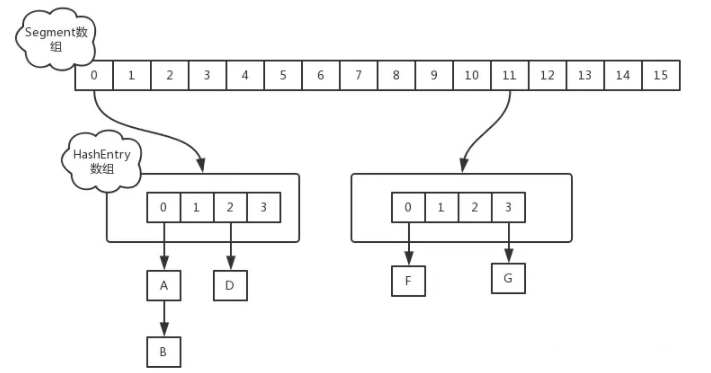
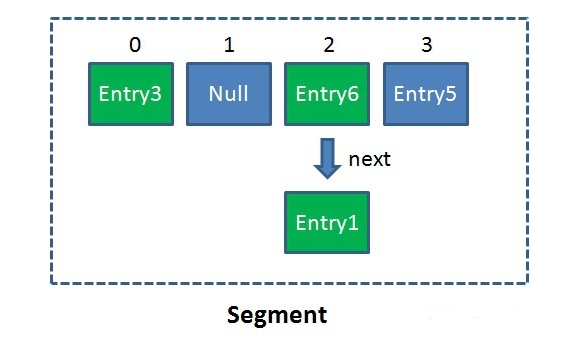
Segment数组的意义就是将一个大的数组分割成多个小的数组来进行加锁,即锁分离技术,而每一个Segment元素存储的是HashEntry数组+链表,相当于一个HashMap的数据结构。Segment包含一个HashEntry数组,数组中的每一个HashEntry既是一个键值对,也是一个链表的头节点。单一的Segment如下:
像这样的Segment对象,在ConcurrentHashMap集合中有多少个呢?有2的N次方个,共同保存在一个名为segments的数组(这个数组是不会扩容的)当中。因此整个ConcurrentHashMap的结构如下:
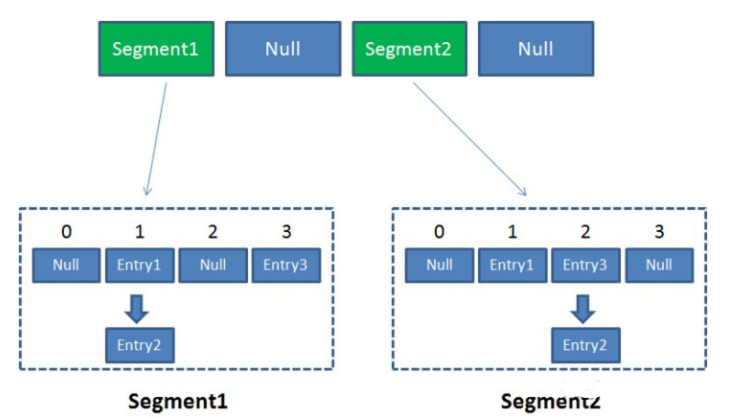
ConcurrentHashMap当中每个Segment各自持有一把锁。在保证线程安全的同时降低了锁的粒度,让并发操作效率更高。
HashEntry大小的计算也是2的N次方(cap <<=1),cap的初始值为1,所以HashEntry最小的容量为2。
另外核心数据 value,以及链表都是volatile修饰的,保证了获取时的可见性。
ConcurrentHashMap 采用了分段锁技术,其中 Segment 继承于 ReentrantLock。不会像 HashTable 那样不管是 put 还是 get 操作都需要做同步处理,理论上 ConcurrentHashMap 支持 CurrencyLevel (Segment 数组数量)的线程并发。每当一个线程占用锁访问一个 Segment 时,不会影响到其他的Segment。
put操作
对于ConcurrentHashMap的数据插入,这里要进行两次hash去定位数据的存储位置。
从上面Segment的继承体系可以看出,Segment实现了ReentrantLock,也就带有锁的功能,当执行put操作时,会进行第一次key的hash来定位Segment的位置,如果该Segment还没有初始化,即通过CAS操作进行赋值;
然后进行第二次hash操作,找到相应的HashEntry的位置,这里会利用继承过来的锁的特性,在将数据插入指定的HashEntry位置时(链表的尾端),会通过继承ReentrantLock的tryLock()方法尝试去获取锁,如果获取成功就直接插入相应的位置,如果已经有线程获取该Segment的锁,那当前线程会以自旋的方式去继续的调用tryLock()方法去获取锁,超过指定次数就挂起,等待唤醒。
get操作
ConcurrentHashMap的get操作跟HashMap类似,只是ConcurrentHashMap第一次需要经过一次hash定位到Segment的位置,然后再hash定位到指定的HashEntry,遍历该HashEntry下的链表进行对比,成功就返回,不成功就返回null。
由于 HashEntry 中的 value 属性是用 volatile 关键词修饰的,保证了内存可见性,所以每次获取时都是最新值。
ConcurrentHashMap 的 get 方法是非常高效的,因为整个过程都不需要加锁。
size操作
计算ConcurrentHashMap的元素大小是一个有趣的问题,因为它是并发操作的,就是在你计算size的时候,它还在并发的插入数据,可能会导致你计算出来的size和你实际的size有相差(在你return size的时候,插入了多个数据),要解决这个问题,JDK1.7版本用两种方案:
- 第一种方案会使用不加锁的模式去尝试多次计算ConcurrentHashMap的size,最多三次,比较前后两次计算的结果,结果一致就认为当前没有元素加入,计算的结果是准确的。
- 如果第一种方案不符合,它就会给每个Segment加上锁,然后计算ConcurrentHashMap的size返回。
JDK1.8 ConcurrentHashMap实现原理
数据结构
JDK1.8的实现已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized和CAS来操作,整个看起来就像是优化过且线程安全的HashMap,虽然在JDK1.8中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本。
另外,将 1.7 中存放数据的 HashEntry 改为 Node,但作用都是相同的。其中的 val、next 都用了 volatile 修饰,保证了可见性。
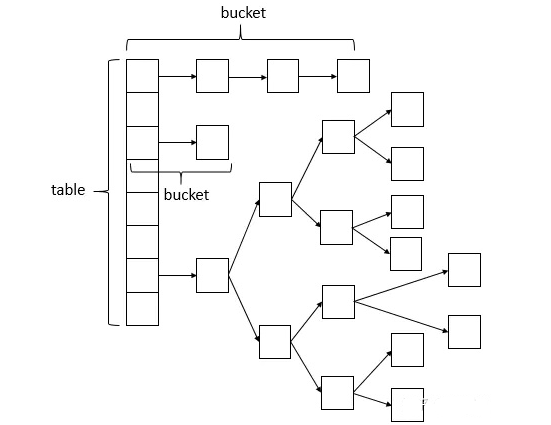
put()方法
这个put的过程很清晰,对当前的table进行无条件自循环直到put成功,可以分成以下六步流程来概述:
- 如果没有初始化就先调用initTable()方法来进行初始化过程;
- 如果没有hash冲突就直接调用Unsafe的方法CAS插入该元素;
- 如果还在进行扩容操作就先进行扩容;
- 如果存在hash冲突,就加锁来保证线程安全,这里有两种情况,一种是链表形式就直接遍历到尾端插入,一种是红黑树就按照红黑树结构插入;
- 最后一个如果该链表的数量大于阈值8,就要先转换成黑红树的结构,break再一次进入循环;
- 如果添加成功就调用addCount()方法统计size,并且检查是否需要扩容。
get()方法
ConcurrentHashMap的get操作的流程很简单,也很清晰,可以分为三个步骤来描述:
计算hash值,定位到该table索引位置,如果是首节点符合就返回;
如果遇到扩容的时候,会调用标志正在扩容节点ForwardingNode的find方法,查找该节点,匹配就返回(会让 get 操作在新
table 进行搜索);
以上都不符合的话,就往下遍历节点,匹配就返回,否则最后就返回null。
size方法
size 计算实际发生在 put,remove 改变集合元素的操作之中:
- 没有竞争发生,向 baseCount 累加计数;
- 有竞争发生,新建 counterCells,向其中的一个 cell 累加计数。
使用一个volatile类型的变量baseCount记录元素的个数,当插入新数据或则删除数据时,会通过addCount()方法更新baseCount。因为元素个数保存baseCount中,部分元素的变化个数保存在CounterCell数组中,通过累加baseCount和CounterCell数组中的数量,即可得到元素的总个数。
1.7和1.8的区别
JDK1.7:ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。
- Segment实际继承自可重入锁(ReentrantLock),在ConcurrentHashMap里扮演锁的角色;HashEntry则用于存储键值对数据。
一个ConcurrentHashMap里包含一个Segment数组,每个Segment里包含一个HashEntry数组,我们称之为table,每个HashEntry是一个链表结构的元素。 - 初始化有三个参数:initialCapacity:初始容量大小 ,默认16。loadFactor, 扩容因子,默认0.75,当一个Segment存储的元素数量大于initialCapacity* loadFactor时,该Segment会进行一次扩容。
- concurrencyLevel 并发度,默认16。并发度可以理解为程序运行时能够同时更新ConccurentHashMap且不产生锁竞争的最大线程数,即ConcurrentHashMap中的分段锁个数,即Segment[]的数组长度。如果并发度设置的过小,会带来严重的锁竞争问题;如果并发度设置的过大,原本位于同一个Segment内的访问会扩散到不同的Segment中,CPU cache命中率会下降,从而引起程序性能下降。
- Segment实际继承自可重入锁(ReentrantLock),在ConcurrentHashMap里扮演锁的角色;HashEntry则用于存储键值对数据。
JDK1.8:已摒弃Segment的概念,直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized和CAS来操作,是优化过且线程安全的HashMap。在JDK1.8中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本。
- JDK1.8取消了segment数组,直接用table保存数据,锁的粒度更小,减少并发冲突的概率。
- JDK1.8存储数据时采用了链表+红黑树的形式,纯链表的形式时间复杂度为O(n),红黑树则为O(logn),性能提升很大;
JDK1.8的实现降低锁的粒度,JDK1.7版本锁的粒度是基于Segment的,包含多个HashEntry,而JDK1.8锁的粒度就是HashEntry(首节点); - JDK1.8版本的数据结构变得更加简单,使得操作也更加清晰流畅,使用synchronized来进行同步,由于粒度的降低,实现的复杂度增加;
- JDK1.8使用内置锁synchronized来代替重入锁ReentrantLock。
JDK 8 ConcurrentHashMap源码分析
重要属性和内部类
1 | // 默认为 0 |
重要方法
1 | // 获取 Node[] 中第 i 个 Node |
构造器分析
可以看到实现了懒惰初始化,在构造方法中仅仅计算了 table 的大小,以后在第一次使用时才会真正创建。
1 | public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) { |
get 流程
1 | public V get(Object key) { |
put 流程
以下数组简称(table),链表简称(bin)
1 | public V put(K key, V value) { |
size 计算流程
1 | public int size() { |
Java 8 数组(Node) +( 链表 Node | 红黑树 TreeNode ) 以下数组简称(table),链表简称(bin)。
初始化,使用 cas 来保证并发安全,懒惰初始化 table;
树化,当 table.length < 64 时,先尝试扩容,超过 64 时,并且 bin.length > 8 时,会将链表树化,树化过程会用 synchronized 锁住链表头;
put,如果该 bin 尚未创建,只需要使用 cas 创建 bin;如果已经有了,锁住链表头进行后续 put 操作,元素添加至 bin 的尾部;
get,无锁操作仅需要保证可见性,扩容过程中 get 操作拿到的是 ForwardingNode 它会让 get 操作在新table 进行搜索;
扩容,扩容时以 bin 为单位进行,需要对 bin 进行 synchronized,但这时妙的是其它竞争线程也不是无事可做,它们会帮助把其它 bin 进行扩容,扩容时平均只有 1/6 的节点会把复制到新 table 中
size,元素个数保存在 baseCount 中,并发时的个数变动保存在 CounterCell[] 当中。最后统计数量时累加即可。
 微信
微信 支付宝
支付宝